def resnet18(pretrained=False, **kwargs):
"""
Constructs a ResNet-18 model.
Args:
pretrained (bool):If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
定义Resnet34
def resnet34(pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
return model
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
下面我们分别看看这两个过程:
网络的forward过程
def forward(self, x): #x代表输入
x = self.conv1(x) #进过卷积层1
x = self.bn1(x) #bn1层
x = self.relu(x) #relu激活
x = self.maxpool(x) #最大池化
x = self.layer1(x) #卷积块1
x = self.layer2(x) #卷积块2
x = self.layer3(x) #卷积块3
x = self.layer4(x) #卷积块4
x = self.avgpool(x) #平均池化
x = x.view(x.size(0), -1) #二维变成变成一维向量
x = self.fc(x) #全连接层
return x
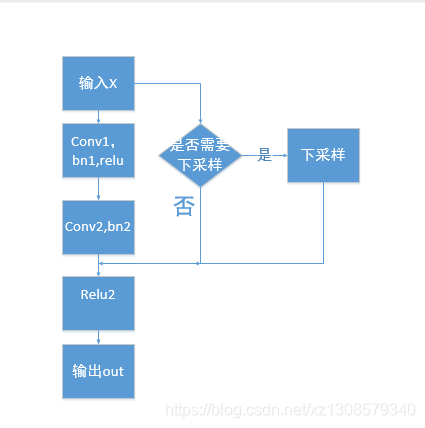
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
我画个流程图来表示一下
画的比较丑,不过基本意思在里面了,
根据论文的描述,x是否需要下采样由x与out是否大小一样决定,
假如进过conv2和bn2后的结果我们称之为 P
假设x的大小为wHchannel1
如果P的大小也是wHchannel1
则无需下采样
out = relu(P + X)
out的大小为W * H *(channel1+channel2),
如果P的大小是W/2 * H/2 * channel
则X需要下采样后才能与P相加,
out = relu(P+ X下采样)
out的大小为W/2 * H/2 * (channel1+channel2)