一、问题
故事起源于一个查询错漏率的报表:有两个查询结果,分别是报告已经添加的项目和报告应该添加的项目,求报告无遗漏率
何为无遗漏?即,应该添加的项目已经被全部添加
报告无遗漏率也就是无遗漏报告数占报告总数的比率
这里以两个报告示例(分别是已全部添加和有遗漏的报告)
首先,查出第一个结果——报告应该添加的项目
SELECT
r.id AS 报告ID,m.project_id 应添加项目
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
RIGHT JOIN application_sample_item si ON s.id=si.sample_id
RIGHT JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id;
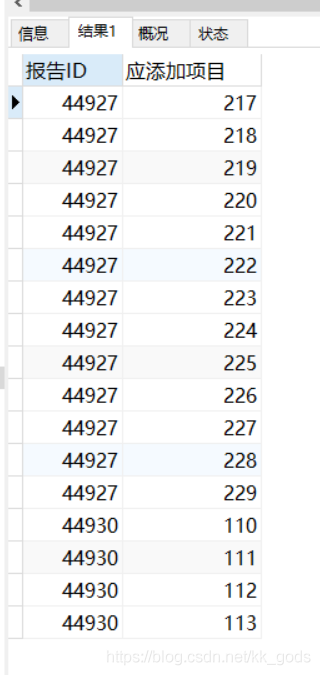
然后,再查出第二个结果——报告已经添加的项目
SELECT r.id AS 报告ID,i.project_id AS 已添加项目
FROM report r
RIGHT JOIN report_item i ON r.id=i.report_id
WHERE r.id IN ('44930','44927');
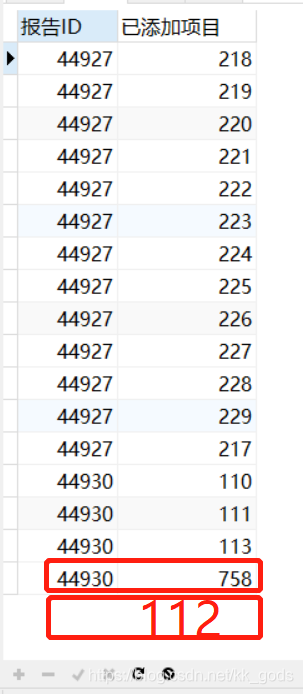
以上就是我们要比较的结果集,不难看出报告44927是无遗漏的,而44930虽然项目数量一致,但实际是多添加了项目758,缺少了项目112,是有遗漏的报告
二、解决方案
从问题看,显然是一个判断是否为子集的问题。可以分别遍历已添加的项目和应该添加的项目,如果应该添加的项目在已添加的项目中都能匹配上,即代表应该添加的项目是已添加的项目子集,也就是无遗漏。
通过循环遍历比较确实可以解决这个问题,但是SQL中出现笛卡儿积的交叉连接往往意味着开销巨大,查询速度慢,那么有没有办法避免这一问题呢?
方案一:
借助于函数 FIND_IN_SET和GROUP_CONCAT, 首先认识下两个函数
FIND_IN_SET(str,strlist)
- str: 需要查询的字符串
- strlist: 参数以英文”,”分隔,如 (1,2,6,8,10,22)
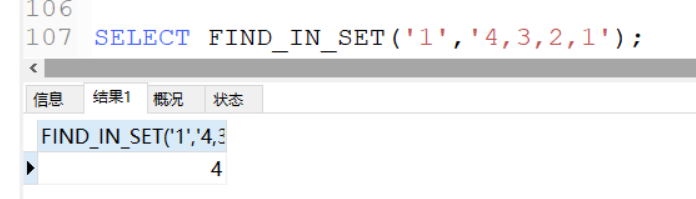
FIND_IN_SET 函数返回了需要查询的字符串在目标字符串的位置
GROUP_CONCAT( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
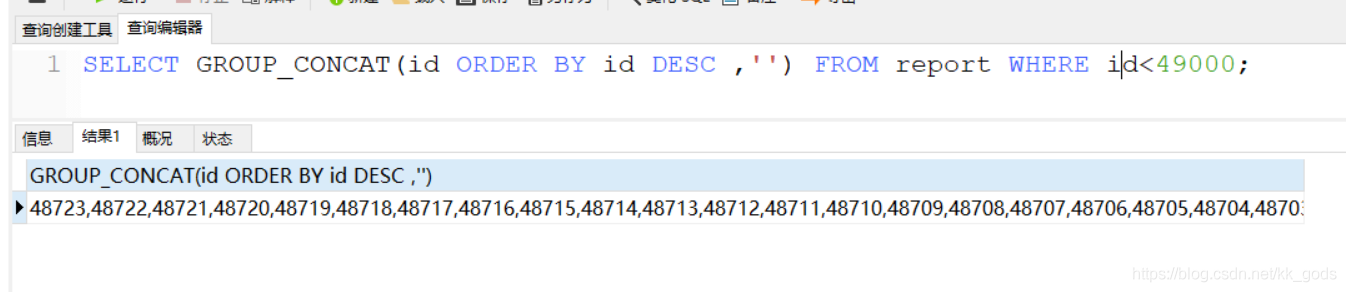
GROUP_CONCAT()函数可以将多条记录的同一字段的值,拼接成一条记录返回。默认以英文‘,'分割。
但是,GROUP_CONCAT()默认长度为1024
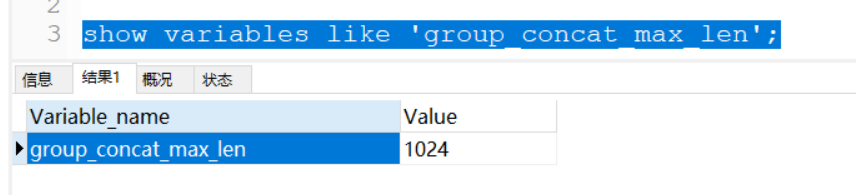
所以,如果需要拼接的长度超过1024将会导致截取不全,需要修改长度
SET GLOBAL group_concat_max_len=102400;
SET SESSION group_concat_max_len=102400;
从上述两个函数介绍中,我们发现FIND_IN_SET和GROUP_CONCAT都以英文‘,'分割(加粗标识)
所以,我们可以用GROUP_CONCAT将已添加项目的项目连接为一个字符串,然后再用FIND_IN_SET逐一查询应添加项目是否都存在于字符串
1、修改问题中描述中的SQL,用GROUP_CONCAT将已添加项目的项目连接为一个字符串
SELECT r.id,GROUP_CONCAT(i.project_id ORDER BY i.project_id,'') AS 已添加项目列表
FROM report r
LEFT JOIN report_item i ON r.id=i.report_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id;

2、用FIND_IN_SET逐一查询应添加项目是否都存在于字符串
SELECT Q.id,FIND_IN_SET(W.应添加项目列表,Q.已添加项目列表) AS 是否遗漏
FROM
(
-- 报告已经添加的项目
SELECT r.id,GROUP_CONCAT(i.project_id ORDER BY i.project_id,'') AS 已添加项目列表
FROM report r
LEFT JOIN report_item i ON r.id=i.report_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id
)Q,
(
-- 报告应该添加的项目
SELECT
r.id,s.app_id,m.project_id 应添加项目列表
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)W
WHERE Q.id=W.id;
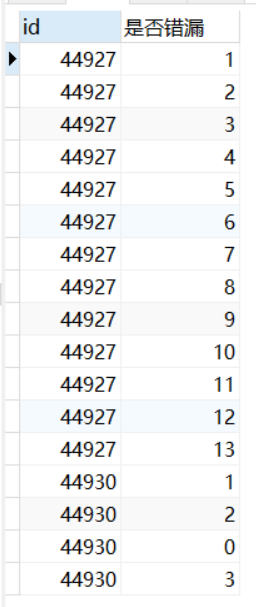
3、过滤掉有遗漏的报告
SELECT Q.id,CASE WHEN FIND_IN_SET(W.应添加项目列表,Q.已添加项目列表)>0 THEN 1 ELSE 0 END AS 是否遗漏
FROM
(
-- 报告已经添加的项目
SELECT r.id,GROUP_CONCAT(i.project_id ORDER BY i.project_id,'') AS 已添加项目列表
FROM report r
LEFT JOIN report_item i ON r.id=i.report_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id
)Q,
(
-- 报告应该添加的项目
SELECT
r.id,s.app_id,m.project_id 应添加项目列表
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)W
WHERE Q.id=W.id
GROUP BY Q.id
HAVING COUNT(`是否遗漏`)=SUM(`是否遗漏`);
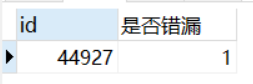
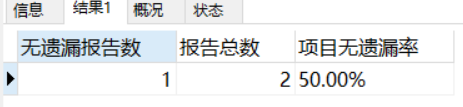
4、我们的最终目标是求无遗漏率
SELECT COUNT(X.id) 无遗漏报告数,Y.total 报告总数, CONCAT(FORMAT(COUNT(X.id)/Y.total*100,2),'%') AS 项目无遗漏率 FROM
(
SELECT Q.id,CASE WHEN FIND_IN_SET(W.应添加项目列表,Q.已添加项目列表)>0 THEN 1 ELSE 0 END AS 是否遗漏
FROM
(
-- 报告已经添加的项目
SELECT r.id,GROUP_CONCAT(i.project_id ORDER BY i.project_id,'') AS 已添加项目列表
FROM report r
LEFT JOIN report_item i ON r.id=i.report_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id
)Q,
(
-- 报告应该添加的项目
SELECT
r.id,s.app_id,m.project_id 应添加项目列表
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)W
WHERE Q.id=W.id
GROUP BY Q.id
HAVING COUNT(`是否遗漏`)=SUM(`是否遗漏`)
)X,
(
-- 总报告数
SELECT COUNT(E.nums) AS total FROM
(
SELECT COUNT(r.id) AS nums FROM report r
WHERE r.id IN ('44930','44927')
GROUP BY r.id
)E
)Y
;
方案二:
上述方案一虽然避免了逐行遍历对比,但本质上还是对项目的逐一对比,那么有没有什么方式可以不用对比呢?
答案当然是有的。我们可以根据统计数量判断是否完全包含。
1、使用union all 将已添加项目与应添加项目联表,不去重
(
-- 应该添加的项目
SELECT
r.id,m.project_id
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)
UNION ALL
(
-- 已经添加的项目
select r.id,i.project_id from report r,report_item i
where r.id = i.report_id and r.id IN ('44930','44927')
group by r.app_id,i.project_id
)
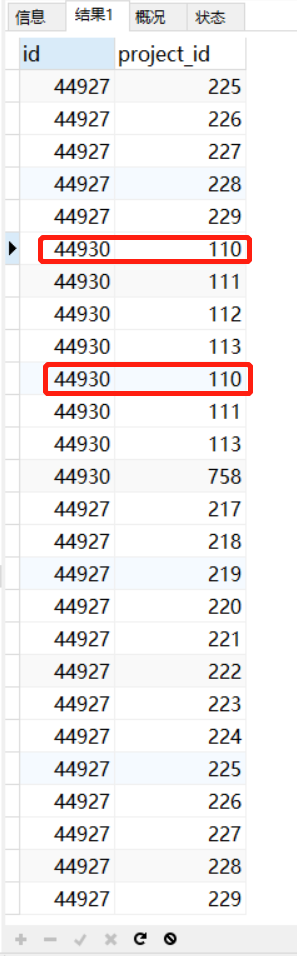
从结果可以看出,项目同一个报告下有重复的项目,分别代表了应该添加和已经添加的项目
2、根据联表结果,统计报告重合的项目数量
# 应该添加与已经添加的项目重叠数量
select tt.id,count(*) count from
(
select t.id,t.project_id,count(*) from
(
(
-- 应该添加的项目
SELECT
r.id,m.project_id
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)
UNION ALL
(
-- 已经添加的项目
select r.id,i.project_id from report r,report_item i
where r.id = i.report_id and r.id IN ('44930','44927')
group by r.app_id,i.project_id
)
) t
GROUP BY t.id,t.project_id
HAVING count(*) >1
) tt group by tt.id
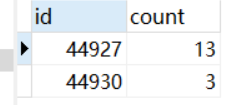
3、将第二步的数量与应该添加的数量作比较,如果相等,则代表无遗漏
select bb.id,aa.count 已添加,bb.count 需添加,
CASE WHEN aa.count/bb.count=1 THEN 1
ELSE 0
END AS '是否遗漏'
from
(
# 应该添加与已经添加的项目重叠数量
select tt.id,count(*) count from
(
select t.id,t.project_id,count(*) from
(
(
-- 应该添加的项目
SELECT
r.id,m.project_id
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)
UNION ALL
(
-- 已经添加的项目
select r.id,i.project_id from report r,report_item i
where r.id = i.report_id and r.id IN ('44930','44927')
group by r.app_id,i.project_id
)
) t
GROUP BY t.id,t.project_id
HAVING count(*) >1
) tt group by tt.id
) aa RIGHT JOIN
(
-- 应该添加的项目数量
SELECT
r.id,s.app_id,COUNT(m.project_id) count
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id
ORDER BY r.id,m.project_id
) bb ON aa.id = bb.id
ORDER BY aa.id
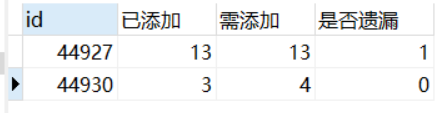
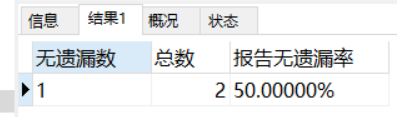
4、求出无遗漏率
select
SUM(asr.`是否遗漏`) AS 无遗漏数,COUNT(asr.id) AS 总数,CONCAT(FORMAT(SUM(asr.`是否遗漏`)/COUNT(asr.id)*100,5),'%') AS 报告无遗漏率
from
(
select bb.id,aa.count 已添加,bb.count 需添加,
CASE WHEN aa.count/bb.count=1 THEN 1
ELSE 0
END AS '是否遗漏'
from
(
# 应该添加与已经添加的项目重叠数量
select tt.id,count(*) count from
(
select t.id,t.project_id,count(*) from
(
(
-- 应该添加的项目
SELECT
r.id,m.project_id
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)
UNION ALL
(
-- 已经添加的项目
select r.id,i.project_id from report r,report_item i
where r.id = i.report_id and r.id IN ('44930','44927')
group by r.app_id,i.project_id
)
) t
GROUP BY t.id,t.project_id
HAVING count(*) >1
) tt group by tt.id
) aa RIGHT JOIN
(
-- 应该添加的项目数量
SELECT
r.id,s.app_id,COUNT(m.project_id) count
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id
ORDER BY r.id,m.project_id
) bb ON aa.id = bb.id
ORDER BY aa.id
) asr;
到此这篇关于mysql 判断是否为子集的方法步骤的文章就介绍到这了,更多相关mysql 判断是否子集内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- MySql8 WITH RECURSIVE递归查询父子集的方法
