1.scrapy_splash是scrapy的一个组件
scrapy_splash加载js数据基于Splash来实现的
Splash是一个Javascrapy渲染服务,它是一个实现HTTP API的轻量级浏览器,Splash是用Python和Lua语言实现的,基于Twisted和QT等模块构建
使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后的网页源代码
2.scrapy_splash的作用
scrpay_splash能够模拟浏览器加载js,并返回js运行后的数据
3.scrapy_splash的环境安装
3.1 使用splash的docker镜像
docker info 查看docker信息
docker images 查看所有镜像
docker pull scrapinghub/splash 安装scrapinghub/splash
docker run -p 8050:8050 scrapinghub/splash 指定8050端口运行
3.2.pip install scrapy-splash
3.3.scrapy 配置:
SPLASH_URL = 'http://localhost:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
3.4.scrapy 使用
from scrapy_splash import SplashRequest
yield SplashRequest(self.start_urls[0], callback=self.parse, args={'wait': 0.5})
4.测试代码:
import datetime
import os
import scrapy
from scrapy_splash import SplashRequest
from ..settings import LOG_DIR
class SplashSpider(scrapy.Spider):
name = 'splash'
allowed_domains = ['biqugedu.com']
start_urls = ['http://www.biqugedu.com/0_25/']
custom_settings = {
'LOG_FILE': os.path.join(LOG_DIR, '%s_%s.log' % (name, datetime.date.today().strftime('%Y-%m-%d'))),
'LOG_LEVEL': 'INFO',
'CONCURRENT_REQUESTS': 8,
'AUTOTHROTTLE_ENABLED': True,
'AUTOTHROTTLE_TARGET_CONCURRENCY': 8,
'SPLASH_URL': 'http://localhost:8050',
'DOWNLOADER_MIDDLEWARES': {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
},
'SPIDER_MIDDLEWARES': {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
},
'DUPEFILTER_CLASS': 'scrapy_splash.SplashAwareDupeFilter',
'HTTPCACHE_STORAGE': 'scrapy_splash.SplashAwareFSCacheStorage',
}
def start_requests(self):
yield SplashRequest(self.start_urls[0], callback=self.parse, args={'wait': 0.5})
def parse(self, response):
"""
:param response:
:return:
"""
response_str = response.body.decode('utf-8', 'ignore')
self.logger.info(response_str)
self.logger.info(response_str.find('http://www.biqugedu.com/files/article/image/0/25/25s.jpg'))
scrapy-splash接收到js请求:
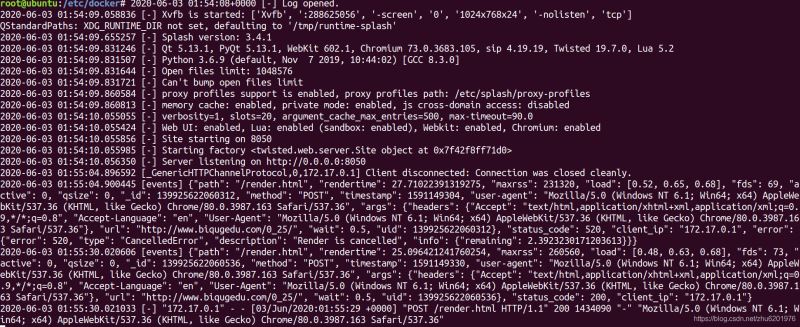
到此这篇关于scrapy-splash简单使用详解的文章就介绍到这了,更多相关scrapy-splash 使用内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- 爬虫进阶-JS自动渲染之Scrapy_splash组件的使用

