目录
- 一、实现数据解析
- 二、安装库
- 三、bs4 的用法
- 四、爬取图片
- 五、爬取三国演义
一、实现数据解析
因为正则表达式本身有难度,所以在这里为大家介绍一下 bs4 实现数据解析。除此之外还有 xpath 解析。因为 xpath 不仅可以在 python 中使用,所以 bs4 和 正则解析一样,仅仅是简单地写两个案例(爬取可翻页的图片,以及爬取三国演义)。以后的重点会在 xpath 上。
二、安装库
闲话少说,我们先来安装 bs4 相关的外来库。比较简单。
1.首先打开 cmd 命令面板,依次安装bs4 和 lxml。
2. 命令分别是 pip install bs4 和 pip install lxml 。
3. 安装完成后我们可以试着调用他们,看看会不会报错。
因为本人水平有限,所以如果出现报错,兄弟们还是百度一下好啦。(总不至于 cmd 命令打错了吧 ~~)
三、bs4 的用法
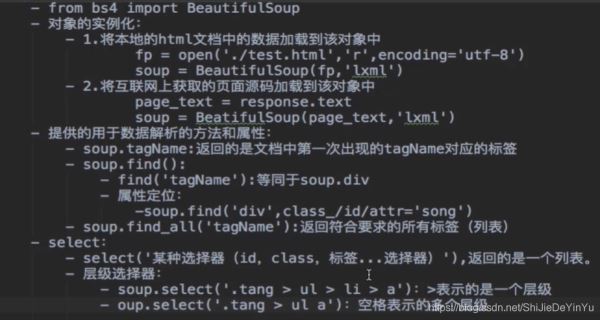
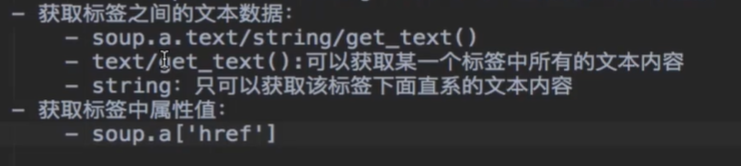
闲话少说,先简单介绍一下 bs4 的用法。
四、爬取图片
import requests
from bs4 import BeautifulSoup
import os
if __name__ == "__main__":
# 创建文件夹
if not os.path.exists("./糗图(bs4)"):
os.mkdir("./糗图(bs4)")
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定 url
for i in range(1, 3): # 翻两页
url = "https://www.qiushibaike.com/imgrank/page/%s/" % str(i)
# 获取源码数据
page = requests.get(url = url, headers = header).text
# 数据解析
soup = BeautifulSoup(page, "lxml")
data_list = soup.select(".thumb > a")
for data in data_list:
url = data.img["src"]
title = url.split("/")[-1]
new_url = "https:" + url
photo = requests.get(url = new_url, headers = header).content
# 存储
with open("./糗图(bs4)/" + title, "wb") as fp:
fp.write(photo)
print(title, "下载完成!!!")
print("over!!!")
五、爬取三国演义
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
# UA 伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
# URL
url = "http://sanguo.5000yan.com/"
# 请求命令
page_text = requests.get(url = url, headers = header)
page_text.encoding = "utf-8"
page_text = page_text.text
soup = BeautifulSoup(page_text, "lxml")
# bs4 解析
li_list = soup.select(".sidamingzhu-list-mulu > ul > li")
for li in li_list:
print(li)
new_url = li.a["href"]
title = li.a.text
# 新的请求命令
response = requests.get(url = new_url, headers = header)
response.encoding = "utf-8"
new_page_text = response.text
new_soup = BeautifulSoup(new_page_text, "lxml")
page = new_soup.find("div", class_ = "grap").text
with open("./三国演义.txt", "a", encoding = "utf-8") as fp:
fp.write("\n" + title + ":" + "\n" + "\n" + page)
print(title + "下载完成!!!")
到此这篇关于python爬虫之bs4数据解析的文章就介绍到这了,更多相关python bs4数据解析内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- python爬虫请求库httpx和parsel解析库的使用测评
- Python爬虫之爬取最新更新的小说网站
- 用Python爬虫破解滑动验证码的案例解析
- Python爬虫爬取爱奇艺电影片库首页的实例代码
- Python爬虫之爬取哔哩哔哩热门视频排行榜
- 上手简单,功能强大的Python爬虫框架——feapder
- python爬虫之爬取百度翻译
- python爬虫基础之简易网页搜集器
- python爬虫之利用selenium模块自动登录CSDN
- python爬虫之爬取笔趣阁小说
- python爬虫之利用Selenium+Requests爬取拉勾网
- python基础之爬虫入门
