| 代码 | 含义 |
|---|---|
| @ | 原生顺序 |
| = | 原生标准 |
| 小端 | |
| > | 大端 |
| ! | 网络顺序 |
示例如下:
import struct
import binascii
values = (2, 'lyj'.encode('UTF-8'), 3.8)
endianness = [
('@', '原生顺序'),
('=', '原生标准'),
('', '小端'),
('>', '大端'),
('!', '网络顺序'),
]
for code, name in endianness:
s = struct.Struct(code + ' I 3s f')
packed_data = s.pack(*values)
print("格式化字符串:", s.format, ' for ', name)
print("大小:", s.size, 'bytes')
print("打包:", binascii.hexlify(packed_data))
print("解包:", s.unpack(packed_data))
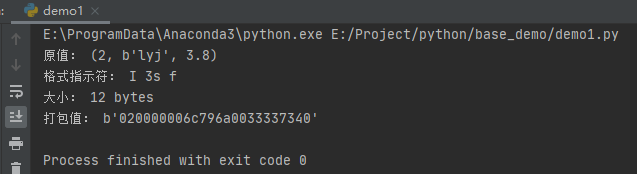
运行之后,效果如下:
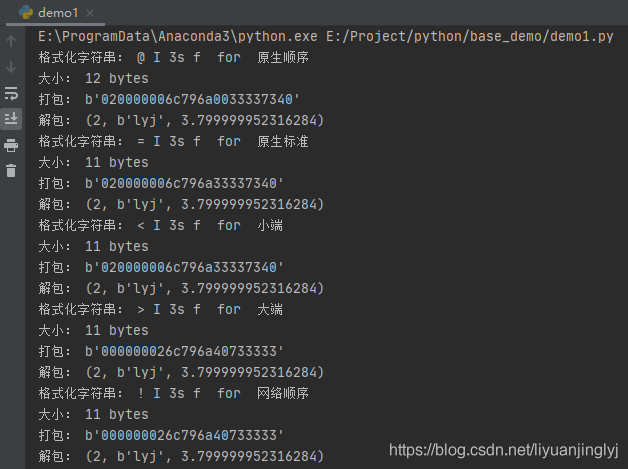
如果想改变字节序来编码,如上面代码所示,只需要改变格式串中提供一个显式的字节序指令,就可以很容易地覆盖这个默认选择。
通常在强调性能的情况下或者向扩展模块传入或传出数据时才会处理二进制打包数据。
为了避免为每个打包结构分配一个新缓冲区所带来的开销,通常情况下,我们使用pack_into()和unpack_from()方法支持直接写入预分配的缓冲区。
示例如下:
import struct
import binascii
import ctypes
import array
values = (2, 'lyj'.encode('UTF-8'), 3.8)
s = struct.Struct('I 3s f')
print("原始值:", values)
b = ctypes.create_string_buffer(s.size)
print("打包之前(缓冲区的值):", binascii.hexlify(b.raw))
s.pack_into(b, 0, *values)
print("打包之后(缓冲区的值):", binascii.hexlify(b.raw))
print("解包:", s.unpack_from(b, 0))
a = array.array('b', b'\0' * s.size)
print("打包之前(缓冲区的值):", binascii.hexlify(a))
s.pack_into(a, 0, *values)
print('打包之后(缓冲区的值):', binascii.hexlify(a))
print("解包:", s.unpack_from(a, 0))
运行之后,效果如下:
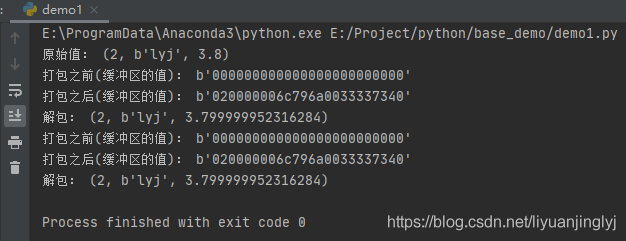
这里通过两种方式,创建缓冲区。其中size属性用于指出缓冲区需要的大小。
到此这篇关于Pytho 二进制数据结构Struct的具体使用的文章就介绍到这了,更多相关Pytho 二进制数据结构Struct内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!