为学习spark,虚拟机中开4台虚拟机安装spark3.0.0
底层hadoop集群已经安装好,见ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境
首先,去http://spark.apache.org/downloads.html下载对应安装包
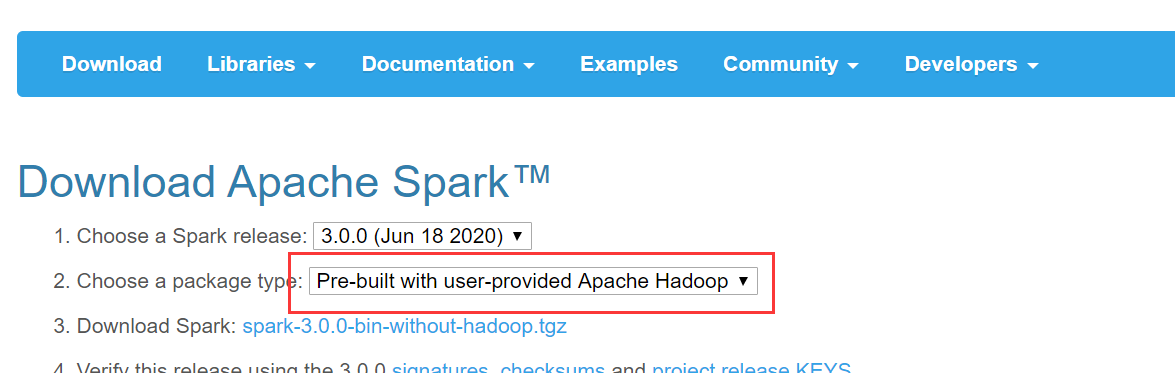
解压
[hadoop@master ~]$ sudo tar -zxf spark-3.0.0-bin-without-hadoop.tgz -C /usr/local
[hadoop@master ~]$ cd /usr/local
[hadoop@master /usr/local]$ sudo mv ./spark-3.0.0-bin-without-hadoop/ spark
[hadoop@master /usr/local]$ sudo chown -R hadoop: ./spark
四个节点都添加环境变量
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
配置spark
spark目录中的conf目录下cp ./conf/spark-env.sh.template ./conf/spark-env.sh后面添加
export SPARK_MASTER_IP=192.168.168.11
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_LOCAL_DIRS=/usr/local/hadoop
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
然后配置work节点,cp ./conf/slaves.template ./conf/slaves修改为
master
slave1
slave2
slave3
写死JAVA_HOME,sbin/spark-config.sh最后添加
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
复制spark目录到其他节点
sudo scp -r /usr/local/spark/ slave1:/usr/local/
sudo scp -r /usr/local/spark/ slave2:/usr/local/
sudo scp -r /usr/local/spark/ slave3:/usr/local/
sudo chown -R hadoop ./spark/
...
启动集群
先启动hadoop集群/usr/local/hadoop/sbin/start-all.sh
然后启动spark集群
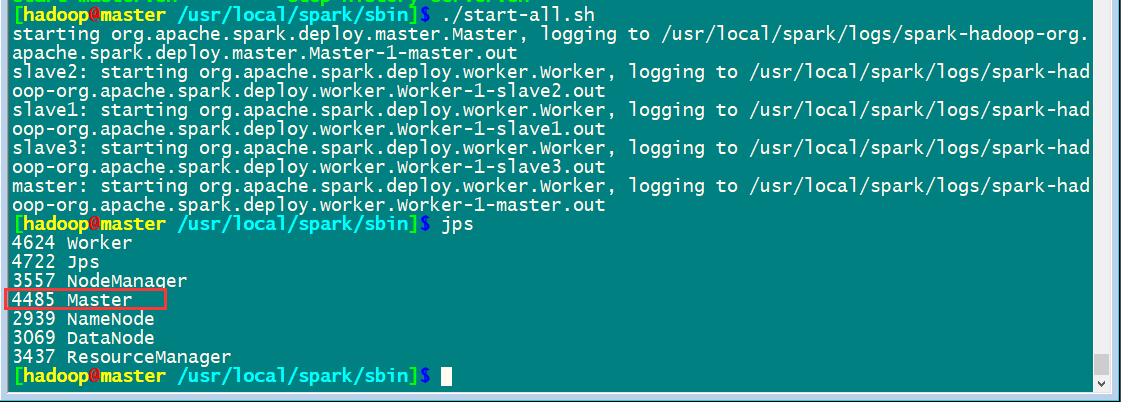
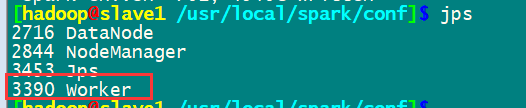
通过master8080端口监控
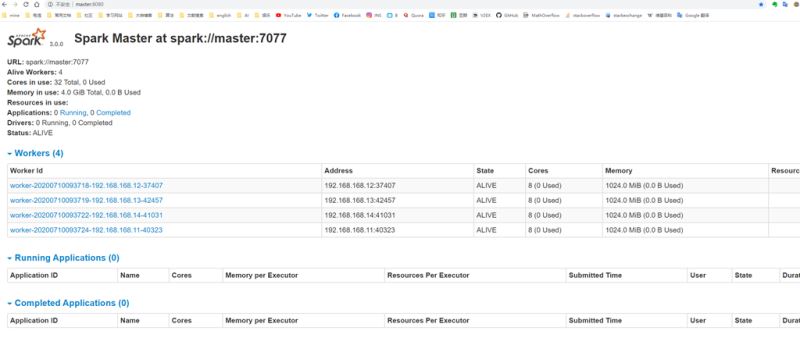
完成安装
到此这篇关于ol7.7安装部署4节点spark3.0.0分布式集群的详细教程的文章就介绍到这了,更多相关ol7.7安装部署spark集群内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- Spark学习笔记 (二)Spark2.3 HA集群的分布式安装图文详解
- Python搭建Spark分布式集群环境
- 使用docker快速搭建Spark集群的方法教程
