POST TIME:2021-07-11 22:17
本页介绍了COCO使用的关键点评估指标。此处提供的评估代码可用于在公开可用的COCO验证集上获得结果。它计算下面描述的多个指标。为了在COCO测试集上获得结果,其中隐藏了实际真值注释,必须将生成的结果上传到评估服务器。下面描述的评估代码用于评估测试集的结果。
COCO关键点任务需要同时检测对象并将其关键点定位(对象位置不在测试时间给出)。由于同时检测和关键点估计的任务是相对较新的,我们选择采用受物体检测度量启发的新颖度量。为了简单起见,我们将这个任务称为关键点检测,将预测算法称为关键点检测器。我们建议在继续之前查看对象检测的评估指标。
评估关键点检测的核心思想是模拟用于目标检测的评估指标,即平均精确度(AP,average precision)和平均召回率(AR,average recall)及其变体。这些度量的核心是实际真实对象和预测对象之间的相似性度量。在对象检测的情况下,IoU(intersection-over-union,叫做交并比)作为这种相似性度量(对于框和片段)。IoU隐含定义了实际真实对象与预测对象之间的匹配,并允许计算精度召回曲线。为了采用AP / AR进行关键点检测,我们只需要定义一个类似的相似性度量。我们通过定义与IoU具有相同作用的对象关键点相似度(OKS,object keypoint similarity)来实现这一点。
对于每个对象,实际真值关键点具有形式[x1,y1,v1,...,xk,yk,vk],其中x,y是关键点位置,v是定义为的可见性标志。v = 0表示未标记,v = 1表示标记但不可见,v = 2表示标记且可见。每个地面真值对象也有一个比例尺s,我们将其定义为物体分段区域的平方根(Each ground truth object also has a scale s which we define as the square root of the object segment area)。有关实际真值格式的详细信息,请参阅下载页面。
对于每个对象,关键点检测器都必须输出关键点位置和对象级别的置信度(object-level confidence)。对象的预测关键点应该具有与实际真值相同的形式:[x1,y1,v1,...,xk,yk,vk]。然而,在评估过程中,检测器的预测vi并不是目前使用的,即关键点检测器不需要预测每个关键点的可见度或置信度(visibilities or confidences)。
我们将对象关键点相似性(OKS)定义为:
OKS = Σi[exp(-di2/2s2κi2)δ(vi>0)] / Σi[δ(vi>0)]
di是每个关键点相应的实际真值和检测到的关键点之间的欧几里德距离,vi是实际真值的可见性标记(检测器的预测vi不被使用)。为了计算OKS,我们通过一个非标准化的高斯将标准差传递给标准偏差sκi,其中s是对象尺度,κi是一个控制衰减的按键控制常数。对于每个关键点,这产生范围在0和1之间的关键点相似性。这些相似性在所有标记的关键点(vi> 0的关键点)上被平均。 未标记的预测关键点(vi = 0)不影响OKS。完美的预测将有OKS = 1,并且所有关键点的偏离超过几个标准差sκi的预测都会有OKS〜0。OKS类似于IoU。考虑到OKS,我们可以计算AP和AR,就像IoU允许我们计算盒/段(box/segment)检测的这些度量一样。
我们调整κi使得OKS是一个感知上有意义且易于解释的相似性度量。首先,在val中使用5000个冗余注释的图像,对于每个关键点类型i,我们测量关于对象尺度s的每个关键点标准偏差σi。那就是我们计算σi2=E[di2/s2]。σi对于不同的关键点有很大的不同:人的关键点(肩膀,膝盖,臀部等shoulders, knees, hips)往往比人的头部(眼睛,鼻子,耳朵eyes, nose, ears)对应的σ大得多。
为了获得感知上有意义和可解释的相似性度量,我们设置κi=2σi。通过设定κi,在di/s的一个,两个和三个标准偏差处,关键点相似度exp(-di2/2s2κi2)取值为e-1/8=0.88, e-4/8=0.61 and e-9/8=0.32。正如所料,人类注释的关键点是正态分布的(忽略偶尔的异常值)。因此,回顾68–95–99.7规则,设定κi=2σi意味着人类注释关键点的68%,95%和99.7%分别具有0.88,0.61或0.32或更高的关键点相似性(在实践中百分比是75%,95%和98.7%)。
OKS是所有(标记的)对象关键点之间的平均关键点相似度。下面我们用κi=2σi来描绘预测的OKS分布,假设每个对象有10个独立的关键点(蓝色曲线),以及在双重注释数据(绿色曲线)上人类OKS得分的实际分布:
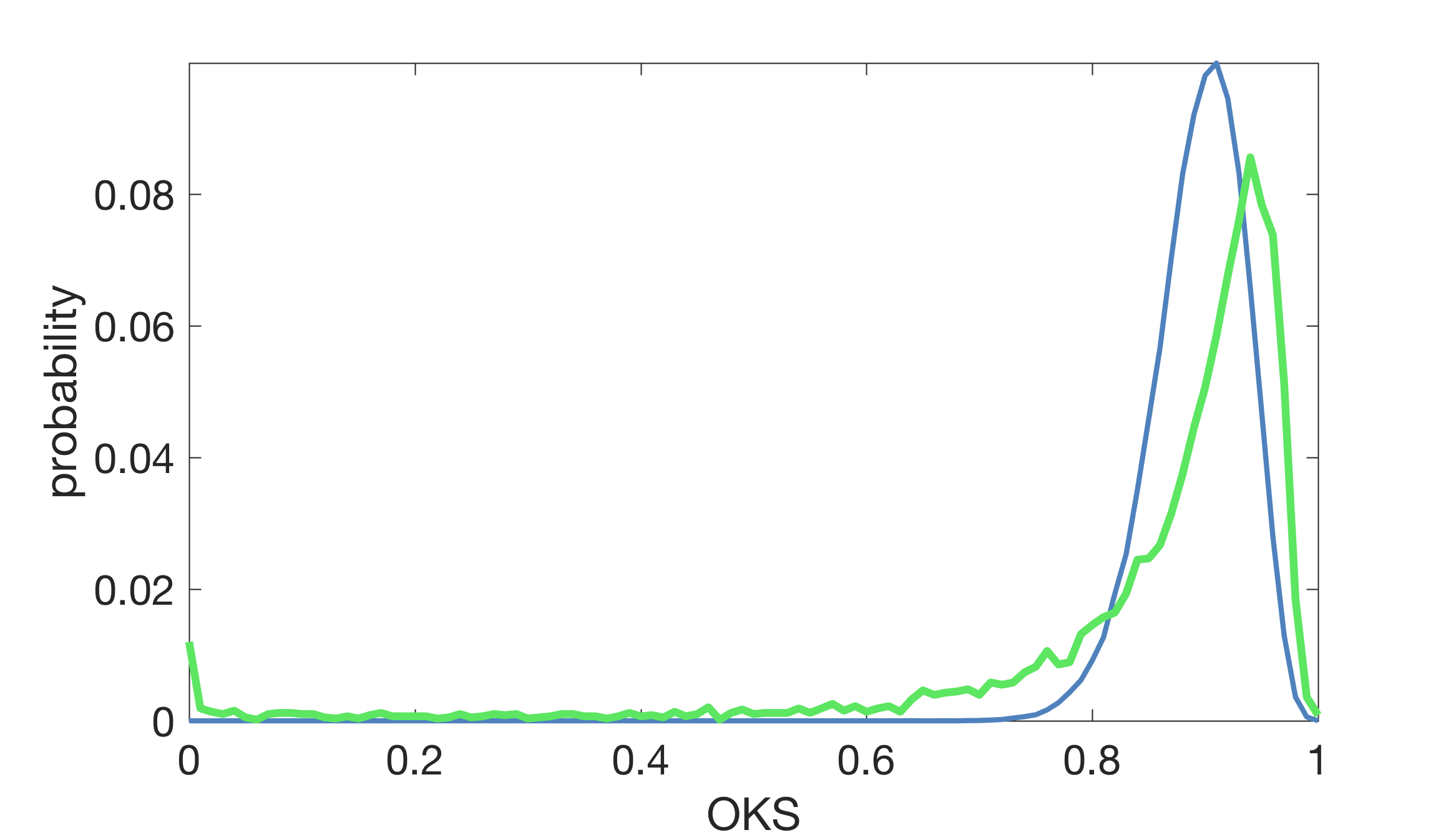
图像不完全匹配的原因有如下几个(1)对象关键点不是独立的,(2)每个对象的标记关键点的数量是不同的,(3)真实数据包含1-2%的异常值(大部分是是由于注释者误将左当成右或当两个人靠近时注释错误造成的)。不过,这种行为大致如预期的那样。我们得出一些关于人类表现的结论(1)在0.50的OKS中,人类的表现几乎完美(95%),(2)人类的中位数为~0.91,(3)在OKS为0.95后人类的表现迅速下降。请注意,此OKS分布可用于预测人类AR(因为AR不依赖于误报)。

Precision 精确率(查准率)。表示正确识别物体A的个数占总识别出的物体个数n的百分数Precision = TP / (TP+FP)
Recall 召回率(查全率)。表示正确识别物体A的个数占测试集中物体A的总个数的百分数Recall = TP / (TP+FN)
fp :false positive误报,即预测错误
fn :false negative漏报,即没有预测到
tp:true positive
tn:true negative
iou:intersection-over-union
Accuracy 准确率。正确分类的样本数除以所有的样本数,正确率越高,分类器越好。Accuracy=(TP+TN)/ (TP+TN+FP+FN)
以上介绍都是基于2分类的,并不是多分类的
以下10个指标用于表征COCO上的关键点检测器的性能:
Average Precision (AP):
AP % AP at OKS=0.50:0.05:0.95(primary challenge metric)
APOKS=.50 % AP at OKS=0.50 (loose metric)
APOKS=.75 % AP at OKS=0.75 (strict metric)
AP Across Scales:
APmedium % AP for medium objects: 322 < area < 962
APlarge % AP for large objects: area > 962
Average Recall (AR):
AR % AR at OKS=0.50:0.05:0.95
AROKS=.50 % AR at OKS=0.50
AROKS=.75 % AR at OKS=0.75
AR Across Scales:
ARmedium % AR for medium objects: 322 < area < 962
ARlarge % AR for large objects: area > 962
1)除非另有说明,否则AP和AR在多个OKS值(0.50:0.05:0.95)之间取平均值。
2)正如所讨论的,我们为每个关键点类型i设置κi=2σi。对于人来说,括号内为σ取值,鼻子(0.026,nose),眼睛(0.025,eyes),耳朵(0.035,ears),肩膀(0.079,shoulders),手肘(0.072,elbows),手腕(0.062,wrists),臀部(0.107,hips),膝盖(0.087,knees),脚踝(0.089,ankles)
3)AP(所有10个OKS阈值的平均值)将决定挑战胜利者。当考虑COCO的关键点性能时,这应该被认为是最重要的一个指标。
4)计算所有度量标准,每个图像最多允许20个最高得分检测(我们使用20个检测,而不是像对象检测挑战那样的100个,因为当前人是唯一具有关键点的类别)。
5)小对象(分段区域面积(segment area)<322)不包含关键点注释。
6)对于没有标注关键点的对象(包括人群),我们使用宽松的启发式方法,以允许根据幻觉关键点(hallucinated keypoints)(置于实际真实对象内以便最大化OKS)匹配检测结果。 这与使用框/段(boxes/segments)来忽略区域的处理非常相似。详细信息请参阅代码。
7)无论被标记的还是可见的关键点的数量如何,每个对象都具有相同的重要性。我们不过滤只有几个关键点的对象,也不会根据存在的关键点的数量来加权对象示例。
评估代码可在COCO github上找到。 具体来说,分别参见Matlab或Python代码中的CocoEval.m或cocoeval.py。另请参阅Matlab或Python代码(demo)中的evalDemo。在运行评估代码之前,请按结果格式页面上描述的格式准备结果,建议先看一下这个格式。
除了评估代码之外,我们还提供了一个函数analyze()来详细分析多实例关键点估计中的错误。这在Ronchi等人的多实例姿态估计的基准和误差诊断中(Benchmarking and Error Diagnosis in Multi-Instance Pose Estimation)被广泛地描述。代码生成这样的图像。
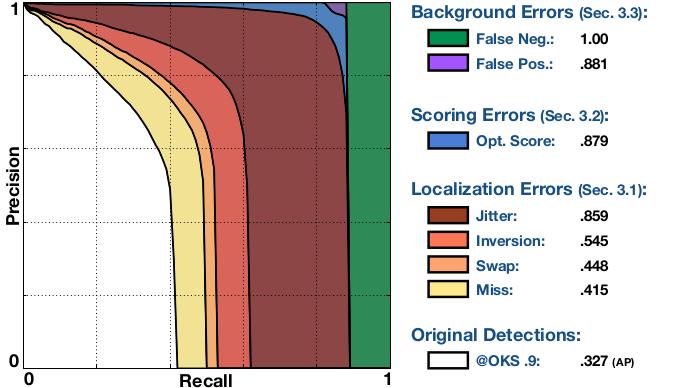
我们展示了来自Zhe Cao等人的2016年ECCV 2016关键挑战获胜者Pose Affinity Fields检测器的分析结果。
该图总结了所有类型的错误对多实例姿态估计算法的性能的影响。它由一系列精确召回(PR,Precision Recall)曲线组成,其中每条曲线保证严格地高于前面的曲线,因为该算法的检测在(任意的)OKS阈值为0.9时被逐步校正。图例显示曲线下面积(AUC,Area Under the Curve)。曲线如下(检查项目页面的完整说明):
1)Original Dts.:在OKS = 0.9(严格的OKS(strict KOS)下的AP)时,原始检测获得的PR,对应于APOKS=.9度量的曲线下面积。
2)Miss:在所有遗漏错误(miss error)都被纠正之后,OKS = 0.9处的PR(严格的OKS下的AP)。缺失(miss)是一个很大的定位误差:检测到的关键点不在正确的身体部位附近。
3)Swap:在所有交换错误(swap errors)都被纠正之后,OKS =0.9处的PR(严格的OKS下的AP)。 交换(swap)是由于图像中不同人的相同身体部分(即右肘right elbow)之间的混淆。
4)Inversion:在所有的逆误差(inversion errors)被纠正之后,OKS =0.9处的PR(严格的OKS下的AP)。 倒置(inversion)是由于同一个人身体部位的混乱(即左右肘)造成的。
5)Jitter:在所有抖动错误(jitter errors)被纠正之后,OKS =0.9处的PR(严格的OKS下的AP)。 抖动(jitter)是一个小的定位误差:检测到的关键点在正确的身体部位附近。
6)Opt. Score:所有的检测算法在评估时使用oracle函数重新计算之后,OKS = 0.9处的PR(AP在严格的OKS)。在检测和实际真值之间匹配的数量重新计分达到最大值。
7)FP:所有背景误报(fps)被移除后的PR。 FP是一个阶跃函数,直到达到最大召回率为1,然后降到0(跨类别平均后曲线更平滑)。
8)FN:删除所有剩余的错误时的PR(微不足道的AP = 1(trivially AP=1))。
在上述检测器的情况下,OKS = 0.9的整体AP是0.327。纠正所有miss错误导致AP的大幅改善到0.415。修正swaps改善到0.488,修正inversions改善到0.545,获得较小的收益。当jitter错误被消除时,获得另一个大的改进,导致0.859的AUC。这显示了如果CMU算法具有关键点的完美定位,性能将会如何。在定位很好的情况下,置信度得分错误(confidence score errors)的影响并不显著,但仍然导致AUC提高约2%(0.879)。最佳评分检测大大减少了背景误报(Background False Positives)的影响,因为检测很少保持不匹配。最后,去除背景错报(Background False Negatives)提供了剩余的AUC以获得完美的表现。总之,在OKS = 0.9时CMU的错误主要是不完美的定位,主要是抖动错误和错过检测(missed detections)。
对于给定的检测器,代码共生成180个图,在3个区域范围(中,大,全)和10个评估阈值(0.5 :0. 05 :0.95)内分析所有错误。分析代码将自动生成一个PDF报告,其中包含总体性能总结,方法行为对不同类型错误的敏感性及其对性能的影响,以及几个最重要的失败案例。
注意:analyze()可能需要很长时间才能运行,请耐心等待。因此,我们通常不会在评估服务器上运行此代码;您必须使用验证集在本地运行代码。你可以在这个GitHub repository中找到analyze()函数。
下一篇:电销机器人目前技术如何?
|
|
|
|||||||||||||||
| 全国咨询热线 | |||||||||||||||||
| 400-1100-266 | |||||||||||||||||
| 在线客服( QQ:340506921 ) | |||||||||||||||||