最近在工作中碰到了 GC 的问题:项目中大量重复地创建许多对象,造成 GC 的工作量巨大,CPU 频繁掉底。准备使用 sync.Pool 来缓存对象,减轻 GC 的消耗。为了用起来更顺畅,我特地研究了一番,形成此文。本文从使用到源码解析,循序渐进,一一道来。
是什么
sync.Pool 是 sync 包下的一个组件,可以作为保存临时取还对象的一个“池子”。个人觉得它的名字有一定的误导性,因为 Pool 里装的对象可以被无通知地被回收,可能 sync.Cache 是一个更合适的名字。
有什么用
对于很多需要重复分配、回收内存的地方,sync.Pool 是一个很好的选择。频繁地分配、回收内存会给 GC 带来一定的负担,严重的时候会引起 CPU 的毛刺,而 sync.Pool 可以将暂时不用的对象缓存起来,待下次需要的时候直接使用,不用再次经过内存分配,复用对象的内存,减轻 GC 的压力,提升系统的性能。
怎么用
首先,sync.Pool 是协程安全的,这对于使用者来说是极其方便的。使用前,设置好对象的 New 函数,用于在 Pool 里没有缓存的对象时,创建一个。之后,在程序的任何地方、任何时候仅通过 Get()、Put() 方法就可以取、还对象了。
下面是 2018 年的时候,《Go 夜读》上关于 sync.Pool 的分享,关于适用场景:
当多个 goroutine 都需要创建同⼀个对象的时候,如果 goroutine 数过多,导致对象的创建数⽬剧增,进⽽导致 GC 压⼒增大。形成 “并发⼤-占⽤内存⼤-GC 缓慢-处理并发能⼒降低-并发更⼤”这样的恶性循环。
在这个时候,需要有⼀个对象池,每个 goroutine 不再⾃⼰单独创建对象,⽽是从对象池中获取出⼀个对象(如果池中已经有的话)。
因此关键思想就是对象的复用,避免重复创建、销毁,下面我们来看看如何使用。
简单的例子
首先来看一个简单的例子:
package main
import (
"fmt"
"sync"
)
var pool *sync.Pool
type Person struct {
Name string
}
func initPool() {
pool = sync.Pool {
New: func()interface{} {
fmt.Println("Creating a new Person")
return new(Person)
},
}
}
func main() {
initPool()
p := pool.Get().(*Person)
fmt.Println("首次从 pool 里获取:", p)
p.Name = "first"
fmt.Printf("设置 p.Name = %s\n", p.Name)
pool.Put(p)
fmt.Println("Pool 里已有一个对象:{first},调用 Get: ", pool.Get().(*Person))
fmt.Println("Pool 没有对象了,调用 Get: ", pool.Get().(*Person))
}
运行结果:
Creating a new Person
首次从 pool 里获取: {}
设置 p.Name = first
Pool 里已有一个对象:{first},Get: {first}
Creating a new Person
Pool 没有对象了,Get: {}
首先,需要初始化 Pool,唯一需要的就是设置好 New 函数。当调用 Get 方法时,如果池子里缓存了对象,就直接返回缓存的对象。如果没有存货,则调用 New 函数创建一个新的对象。
另外,我们发现 Get 方法取出来的对象和上次 Put 进去的对象实际上是同一个,Pool 没有做任何“清空”的处理。但我们不应当对此有任何假设,因为在实际的并发使用场景中,无法保证这种顺序,最好的做法是在 Put 前,将对象清空。
fmt 包如何用
这部分主要看 fmt.Printf 如何使用:
func Printf(format string, a ...interface{}) (n int, err error) {
return Fprintf(os.Stdout, format, a...)
}
继续看 Fprintf:
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error) {
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
p.free()
return
}
Fprintf 函数的参数是一个 io.Writer,Printf 传的是 os.Stdout,相当于直接输出到标准输出。这里的 newPrinter 用的就是 Pool:
// newPrinter allocates a new pp struct or grabs a cached one.
func newPrinter() *pp {
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(p.buf)
return p
}
var ppFree = sync.Pool{
New: func() interface{} { return new(pp) },
}
回到 Fprintf 函数,拿到 pp 指针后,会做一些 format 的操作,并且将 p.buf 里面的内容写入 w。最后,调用 free 函数,将 pp 指针归还到 Pool 中:
// free saves used pp structs in ppFree; avoids an allocation per invocation.
func (p *pp) free() {
if cap(p.buf) > 6410 {
return
}
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}
归还到 Pool 前将对象的一些字段清零,这样,通过 Get 拿到缓存的对象时,就可以安全地使用了。
pool_test
通过 test 文件学习源码是一个很好的途径,因为它代表了“官方”的用法。更重要的是,测试用例会故意测试一些“坑”,学习这些坑,也会让自己在使用的时候就能学会避免。
pool_test 文件里共有 7 个测试,4 个 BechMark。
TestPool 和 TestPoolNew 比较简单,主要是测试 Get/Put 的功能。我们来看下 TestPoolNew:
func TestPoolNew(t *testing.T) {
// disable GC so we can control when it happens.
defer debug.SetGCPercent(debug.SetGCPercent(-1))
i := 0
p := Pool{
New: func() interface{} {
i++
return i
},
}
if v := p.Get(); v != 1 {
t.Fatalf("got %v; want 1", v)
}
if v := p.Get(); v != 2 {
t.Fatalf("got %v; want 2", v)
}
// Make sure that the goroutine doesn't migrate to another P
// between Put and Get calls.
Runtime_procPin()
p.Put(42)
if v := p.Get(); v != 42 {
t.Fatalf("got %v; want 42", v)
}
Runtime_procUnpin()
if v := p.Get(); v != 3 {
t.Fatalf("got %v; want 3", v)
}
}
首先设置了 GC=-1,作用就是停止 GC。那为啥要用 defer?函数都跑完了,还要 defer 干啥。注意到,debug.SetGCPercent 这个函数被调用了两次,而且这个函数返回的是上一次 GC 的值。因此,defer 在这里的用途是还原到调用此函数之前的 GC 设置,也就是恢复现场。
接着,调置了 Pool 的 New 函数:直接返回一个 int,变且每次调用 New,都会自增 1。然后,连续调用了两次 Get 函数,因为这个时候 Pool 里没有缓存的对象,因此每次都会调用 New 创建一个,所以第一次返回 1,第二次返回 2。
然后,调用 Runtime_procPin() 防止 goroutine 被强占,目的是保护接下来的一次 Put 和 Get 操作,使得它们操作的对象都是同一个 P 的“池子”。并且,这次调用 Get 的时候并没有调用 New,因为之前有一次 Put 的操作。
最后,再次调用 Get 操作,因为没有“存货”,因此还是会再次调用 New 创建一个对象。
TestPoolGC 和 TestPoolRelease 则主要测试 GC 对 Pool 里对象的影响。这里用了一个函数,用于计数有多少对象会被 GC 回收:
runtime.SetFinalizer(v, func(vv *string) {
atomic.AddUint32(fin, 1)
})
当垃圾回收检测到 v 是一个不可达的对象时,并且 v 又有一个关联的 Finalizer,就会另起一个 goroutine 调用设置的 finalizer 函数,也就是上面代码里的参数 func。这样,就会让对象 v 重新可达,从而在这次 GC 过程中不被回收。之后,解绑对象 v 和它所关联的 Finalizer,当下次 GC 再次检测到对象 v 不可达时,才会被回收。
TestPoolStress 从名字看,主要是想测一下“压力”,具体操作就是起了 10 个 goroutine 不断地向 Pool 里 Put 对象,然后又 Get 对象,看是否会出错。
TestPoolDequeue 和 TestPoolChain,都调用了 testPoolDequeue,这是具体干活的。它需要传入一个 PoolDequeue 接口:
// poolDequeue testing.
type PoolDequeue interface {
PushHead(val interface{}) bool
PopHead() (interface{}, bool)
PopTail() (interface{}, bool)
}
PoolDequeue 是一个双端队列,可以从头部入队元素,从头部和尾部出队元素。调用函数时,前者传入 NewPoolDequeue(16),后者传入 NewPoolChain(),底层其实都是 poolDequeue 这个结构体。具体来看 testPoolDequeue 做了什么:
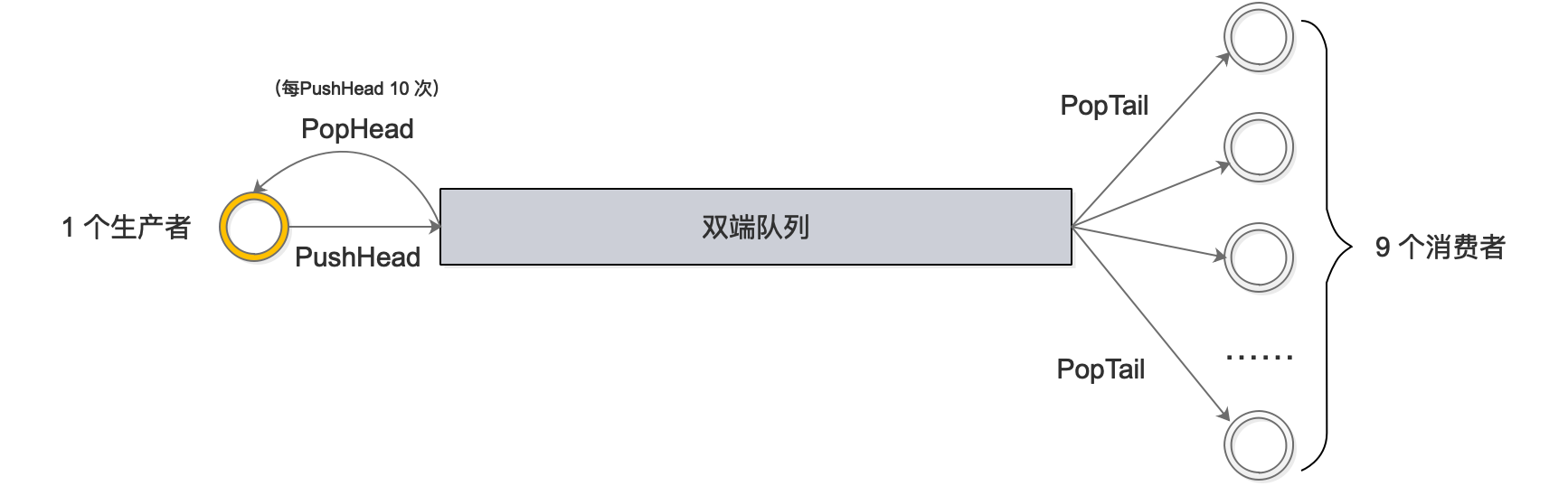
总共起了 10 个 goroutine:1 个生产者,9 个消费者。生产者不断地从队列头 pushHead 元素到双端队列里去,并且每 push 10 次,就 popHead 一次;消费者则一直从队列尾取元素。不论是从队列头还是从队列尾取元素,都会在 map 里做标记,最后检验每个元素是不是只被取出过一次。
剩下的就是 Benchmark 测试了。第一个 BenchmarkPool 比较简单,就是不停地 Put/Get,测试性能。
BenchmarkPoolSTW 函数会先关掉 GC,再向 pool 里 put 10 个对象,然后强制触发 GC,记录 GC 的停顿时间,并且做一个排序,计算 P50 和 P95 的 STW 时间。这个函数可以加入个人的代码库了:
func BenchmarkPoolSTW(b *testing.B) {
// Take control of GC.
defer debug.SetGCPercent(debug.SetGCPercent(-1))
var mstats runtime.MemStats
var pauses []uint64
var p Pool
for i := 0; i b.N; i++ {
// Put a large number of items into a pool.
const N = 100000
var item interface{} = 42
for i := 0; i N; i++ {
p.Put(item)
}
// Do a GC.
runtime.GC()
// Record pause time.
runtime.ReadMemStats(mstats)
pauses = append(pauses, mstats.PauseNs[(mstats.NumGC+255)%256])
}
// Get pause time stats.
sort.Slice(pauses, func(i, j int) bool { return pauses[i] pauses[j] })
var total uint64
for _, ns := range pauses {
total += ns
}
// ns/op for this benchmark is average STW time.
b.ReportMetric(float64(total)/float64(b.N), "ns/op")
b.ReportMetric(float64(pauses[len(pauses)*95/100]), "p95-ns/STW")
b.ReportMetric(float64(pauses[len(pauses)*50/100]), "p50-ns/STW")
}
我在 mac 上跑了一下:
go test -v -run=none -bench=BenchmarkPoolSTW
得到输出:
goos: darwin
goarch: amd64
pkg: sync
BenchmarkPoolSTW-12 361 3708 ns/op 3583 p50-ns/STW 5008 p95-ns/STW
PASS
ok sync 1.481s
最后一个 BenchmarkPoolExpensiveNew 测试当 New 的代价很高时,Pool 的表现。也可以加入个人的代码库。
其他
标准库中 encoding/json 也用到了 sync.Pool 来提升性能。著名的 gin 框架,对 context 取用也到了 sync.Pool。
来看下 gin 如何使用 sync.Pool。设置 New 函数:
engine.pool.New = func() interface{} {
return engine.allocateContext()
}
func (engine *Engine) allocateContext() *Context {
return Context{engine: engine, KeysMutex: sync.RWMutex{}}
}
使用:
// ServeHTTP conforms to the http.Handler interface.
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
c := engine.pool.Get().(*Context)
c.writermem.reset(w)
c.Request = req
c.reset()
engine.handleHTTPRequest(c)
engine.pool.Put(c)
}
先调用 Get 取出来缓存的对象,然后会做一些 reset 操作,再执行 handleHTTPRequest,最后再 Put 回 Pool。
另外,Echo 框架也使⽤了 sync.Pool 来管理 context,并且⼏乎达到了零堆内存分配:
It leverages sync pool to reuse memory and achieve zero dynamic memory allocation with no GC overhead.
源码分析
Pool 结构体
首先来看 Pool 的结构体:
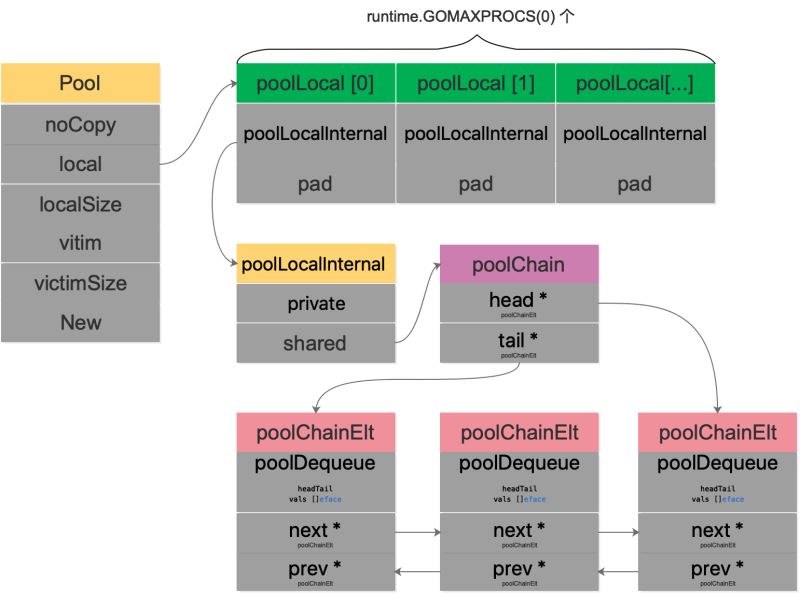
type Pool struct {
noCopy noCopy
// 每个 P 的本地队列,实际类型为 [P]poolLocal
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
// [P]poolLocal的大小
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// 自定义的对象创建回调函数,当 pool 中无可用对象时会调用此函数
New func() interface{}
}
因为 Pool 不希望被复制,所以结构体里有一个 noCopy 的字段,使用 go vet 工具可以检测到用户代码是否复制了 Pool。
noCopy 是 go1.7 开始引入的一个静态检查机制。它不仅仅工作在运行时或标准库,同时也对用户代码有效。
用户只需实现这样的不消耗内存、仅用于静态分析的结构,来保证一个对象在第一次使用后不会发生复制。
实现非常简单:
// noCopy 用于嵌入一个结构体中来保证其第一次使用后不会被复制
//
// 见 https://golang.org/issues/8005#issuecomment-190753527
type noCopy struct{}
// Lock 是一个空操作用来给 `go ve` 的 -copylocks 静态分析
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
local 字段存储指向 [P]poolLocal 数组(严格来说,它是一个切片)的指针,localSize 则表示 local 数组的大小。访问时,P 的 id 对应 [P]poolLocal 下标索引。通过这样的设计,多个 goroutine 使用同一个 Pool 时,减少了竞争,提升了性能。
在一轮 GC 到来时,victim 和 victimSize 会分别“接管” local 和 localSize。victim 的机制用于减少 GC 后冷启动导致的性能抖动,让分配对象更平滑。
Victim Cache 本来是计算机架构里面的一个概念,是 CPU 硬件处理缓存的一种技术,sync.Pool 引入的意图在于降低 GC 压力的同时提高命中率。
当 Pool 没有缓存的对象时,调用 New 方法生成一个新的对象。
type poolLocal struct {
poolLocalInternal
// 将 poolLocal 补齐至两个缓存行的倍数,防止 false sharing,
// 每个缓存行具有 64 bytes,即 512 bit
// 目前我们的处理器一般拥有 32 * 1024 / 64 = 512 条缓存行
// 伪共享,仅占位用,防止在 cache line 上分配多个 poolLocalInternal
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
// Local per-P Pool appendix.
type poolLocalInternal struct {
// P 的私有缓存区,使用时无需要加锁
private interface{}
// 公共缓存区。本地 P 可以 pushHead/popHead;其他 P 则只能 popTail
shared poolChain
}
字段 pad 主要是防止 false sharing,董大的《什么是 cpu cache》里讲得比较好:
现代 cpu 中,cache 都划分成以 cache line (cache block) 为单位,在 x86_64 体系下一般都是 64 字节,cache line 是操作的最小单元。
程序即使只想读内存中的 1 个字节数据,也要同时把附近 63 节字加载到 cache 中,如果读取超个 64 字节,那么就要加载到多个 cache line 中。
简单来说,如果没有 pad 字段,那么当需要访问 0 号索引的 poolLocal 时,CPU 同时会把 0 号和 1 号索引同时加载到 cpu cache。在只修改 0 号索引的情况下,会让 1 号索引的 poolLocal 失效。这样,当其他线程想要读取 1 号索引时,发生 cache miss,还得重新再加载,对性能有损。增加一个 pad,补齐缓存行,让相关的字段能独立地加载到缓存行就不会出现 false sharding 了。
poolChain 是一个双端队列的实现:
type poolChain struct {
// 只有生产者会 push to,不用加锁
head *poolChainElt
// 读写需要原子控制。 pop from
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
// next 被 producer 写,consumer 读。所以只会从 nil 变成 non-nil
// prev 被 consumer 写,producer 读。所以只会从 non-nil 变成 nil
next, prev *poolChainElt
}
type poolDequeue struct {
// The head index is stored in the most-significant bits so
// that we can atomically add to it and the overflow is
// harmless.
// headTail 包含一个 32 位的 head 和一个 32 位的 tail 指针。这两个值都和 len(vals)-1 取模过。
// tail 是队列中最老的数据,head 指向下一个将要填充的 slot
// slots 的有效范围是 [tail, head),由 consumers 持有。
headTail uint64
// vals 是一个存储 interface{} 的环形队列,它的 size 必须是 2 的幂
// 如果 slot 为空,则 vals[i].typ 为空;否则,非空。
// 一个 slot 在这时宣告无效:tail 不指向它了,vals[i].typ 为 nil
// 由 consumer 设置成 nil,由 producer 读
vals []eface
}
poolDequeue 被实现为单生产者、多消费者的固定大小的无锁(atomic 实现) Ring 式队列(底层存储使用数组,使用两个指针标记 head、tail)。生产者可以从 head 插入、head 删除,而消费者仅可从 tail 删除。
headTail 指向队列的头和尾,通过位运算将 head 和 tail 存入 headTail 变量中。
我们用一幅图来完整地描述 Pool 结构体:
结合木白的技术私厨的《请问sync.Pool有什么缺点?》里的一张图,对于双端队列的理解会更容易一些:
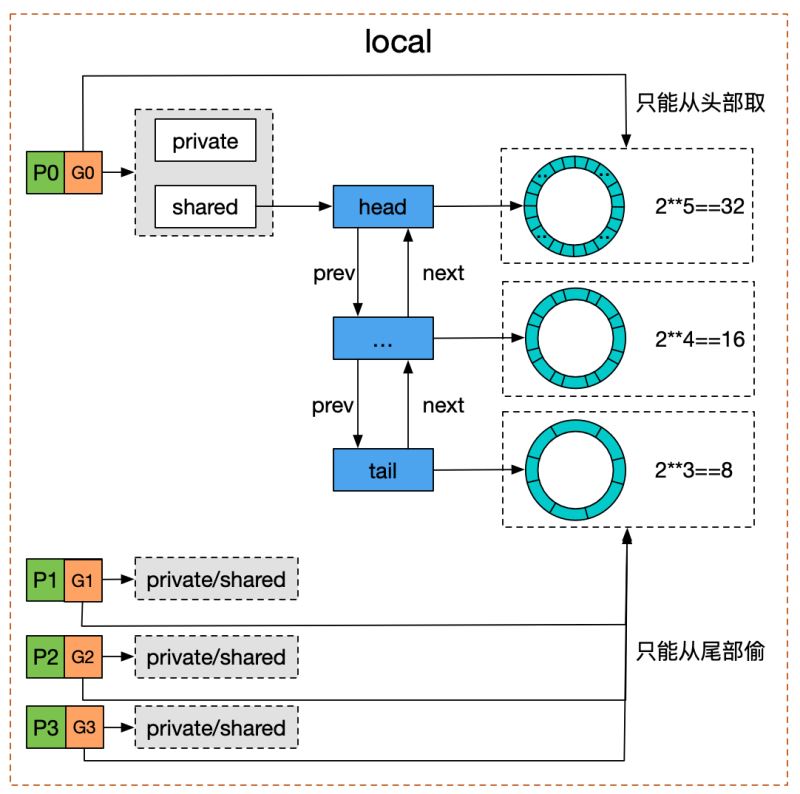
我们看到 Pool 并没有直接使用 poolDequeue,原因是它的大小是固定的,而 Pool 的大小是没有限制的。因此,在 poolDequeue 之上包装了一下,变成了一个 poolChainElt 的双向链表,可以动态增长。
Get
直接上源码:
func (p *Pool) Get() interface{} {
// ......
l, pid := p.pin()
x := l.private
l.private = nil
if x == nil {
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
runtime_procUnpin()
// ......
if x == nil p.New != nil {
x = p.New()
}
return x
}
省略号的内容是 race 相关的,属于阅读源码过程中的一些噪音,暂时注释掉。这样,Get 的整个过程就非常清晰了:
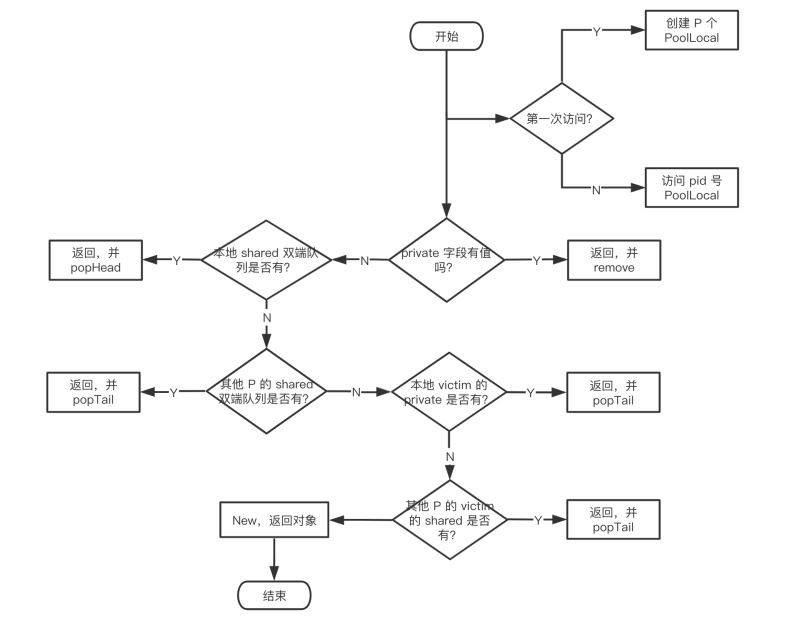
- 首先,调用
p.pin() 函数将当前的 goroutine 和 P 绑定,禁止被抢占,返回当前 P 对应的 poolLocal,以及 pid。
- 然后直接取 l.private,赋值给 x,并置 l.private 为 nil。
- 判断 x 是否为空,若为空,则尝试从 l.shared 的头部 pop 一个对象出来,同时赋值给 x。
- 如果 x 仍然为空,则调用 getSlow 尝试从其他 P 的 shared 双端队列尾部“偷”一个对象出来。
- Pool 的相关操作做完了,调用
runtime_procUnpin() 解除非抢占。
- 最后如果还是没有取到缓存的对象,那就直接调用预先设置好的 New 函数,创建一个出来。
我用一张流程图来展示整个过程:
整体流程梳理完了,我们再来看一下其中的一些关键函数。
pin
先来看 Pool.pin():
// src/sync/pool.go
// 调用方必须在完成取值后调用 runtime_procUnpin() 来取消抢占。
func (p *Pool) pin() (*poolLocal, int) {
pid := runtime_procPin()
s := atomic.LoadUintptr(p.localSize) // load-acquire
l := p.local // load-consume
// 因为可能存在动态的 P(运行时调整 P 的个数)
if uintptr(pid) s {
return indexLocal(l, pid), pid
}
return p.pinSlow()
}
pin 的作用就是将当前 groutine 和 P 绑定在一起,禁止抢占。并且返回对应的 poolLocal 以及 P 的 id。
如果 G 被抢占,则 G 的状态从 running 变成 runnable,会被放回 P 的 localq 或 globaq,等待下一次调度。下次再执行时,就不一定是和现在的 P 相结合了。因为之后会用到 pid,如果被抢占了,有可能接下来使用的 pid 与所绑定的 P 并非同一个。
“绑定”的任务最终交给了 procPin:
// src/runtime/proc.go
func procPin() int {
_g_ := getg()
mp := _g_.m
mp.locks++
return int(mp.p.ptr().id)
}
实现的代码很简洁:将当前 goroutine 绑定的 m 上的一个锁字段 locks 值加 1,即完成了“绑定”。关于 pin 的原理,可以参考《golang的对象池sync.pool源码解读》,文章详细分析了为什么执行 procPin 之后,不可抢占,且 GC 不会清扫 Pool 里的对象。
我们再回到 p.pin(),原子操作取出 p.localSize 和 p.local,如果当前 pid 小于 p.localSize,则直接取 poolLocal 数组中的 pid 索引处的元素。否则,说明 Pool 还没有创建 poolLocal,调用 p.pinSlow() 完成创建工作。
func (p *Pool) pinSlow() (*poolLocal, int) {
// Retry under the mutex.
// Can not lock the mutex while pinned.
runtime_procUnpin()
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
// 没有使用原子操作,因为已经加了全局锁了
s := p.localSize
l := p.local
// 因为 pinSlow 中途可能已经被其他的线程调用,因此这时候需要再次对 pid 进行检查。 如果 pid 在 p.local 大小范围内,则不用创建 poolLocal 切片,直接返回。
if uintptr(pid) s {
return indexLocal(l, pid), pid
}
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
// 当前 P 的数量
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
// 旧的 local 会被回收
atomic.StorePointer(p.local, unsafe.Pointer(local[0])) // store-release
atomic.StoreUintptr(p.localSize, uintptr(size)) // store-release
return local[pid], pid
}
因为要上一把大锁 allPoolsMu,所以函数名带有 slow。我们知道,锁粒度越大,竞争越多,自然就越“slow”。不过要想上锁的话,得先解除“绑定”,锁上之后,再执行“绑定”。原因是锁越大,被阻塞的概率就越大,如果还占着 P,那就浪费资源。
在解除绑定后,pinSlow 可能被其他的线程调用过了,p.local 可能会发生变化。因此这时候需要再次对 pid 进行检查。如果 pid 在 p.localSize 大小范围内,则不用再创建 poolLocal 切片,直接返回。
之后,根据 P 的个数,使用 make 创建切片,包含 runtime.GOMAXPROCS(0) 个 poolLocal,并且使用原子操作设置 p.local 和 p.localSize。
最后,返回 p.local 对应 pid 索引处的元素。
关于这把大锁 allPoolsMu,曹大在《几个 Go 系统可能遇到的锁问题》里讲了一个例子。第三方库用了 sync.Pool,内部有一个结构体 fasttemplate.Template,包含 sync.Pool 字段。而 rd 在使用时,每个请求都会新建这样一个结构体。于是,处理每个请求时,都会尝试从一个空的 Pool 里取缓存的对象,最后 goroutine 都阻塞在了这把大锁上,因为都在尝试执行:allPools = append(allPools, p),从而造成性能问题。
popHead
回到 Get 函数,再来看另一个关键的函数:poolChain.popHead():
func (c *poolChain) popHead() (interface{}, bool) {
d := c.head
for d != nil {
if val, ok := d.popHead(); ok {
return val, ok
}
// There may still be unconsumed elements in the
// previous dequeue, so try backing up.
d = loadPoolChainElt(d.prev)
}
return nil, false
}
popHead 函数只会被 producer 调用。首先拿到头节点:c.head,如果头节点不为空的话,尝试调用头节点的 popHead 方法。注意这两个 popHead 方法实际上并不相同,一个是 poolChain 的,一个是 poolDequeue 的,有疑惑的,不妨回头再看一下 Pool 结构体的图。我们来看 poolDequeue.popHead():
// /usr/local/go/src/sync/poolqueue.go
func (d *poolDequeue) popHead() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(d.headTail)
head, tail := d.unpack(ptrs)
// 判断队列是否为空
if tail == head {
// Queue is empty.
return nil, false
}
// head 位置是队头的前一个位置,所以此处要先退一位。
// 在读出 slot 的 value 之前就把 head 值减 1,取消对这个 slot 的控制
head--
ptrs2 := d.pack(head, tail)
if atomic.CompareAndSwapUint64(d.headTail, ptrs, ptrs2) {
// We successfully took back slot.
slot = d.vals[headuint32(len(d.vals)-1)]
break
}
}
// 取出 val
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
// 重置 slot,typ 和 val 均为 nil
// 这里清空的方式与 popTail 不同,与 pushHead 没有竞争关系,所以不用太小心
*slot = eface{}
return val, true
}
此函数会删掉并且返回 queue 的头节点。但如果 queue 为空的话,返回 false。这里的 queue 存储的实际上就是 Pool 里缓存的对象。
整个函数的核心是一个无限循环,这是 Go 中常用的无锁化编程形式。
首先调用 unpack 函数分离出 head 和 tail 指针,如果 head 和 tail 相等,即首尾相等,那么这个队列就是空的,直接就返回 nil,false。
否则,将 head 指针后移一位,即 head 值减 1,然后调用 pack 打包 head 和 tail 指针。使用 atomic.CompareAndSwapUint64 比较 headTail 在这之间是否有变化,如果没变化,相当于获取到了这把锁,那就更新 headTail 的值。并且把 vals 相应索引处的元素赋值给 slot。
因为 vals 长度实际是只能是 2 的 n 次幂,因此 len(d.vals)-1 实际上得到的值的低 n 位是全 1,它再与 head 相与,实际就是取 head 低 n 位的值。
得到相应 slot 的元素后,经过类型转换并判断是否是 dequeueNil,如果是,说明没取到缓存的对象,返回 nil。
// /usr/local/go/src/sync/poolqueue.go
// 因为使用 nil 代表空的 slots,因此使用 dequeueNil 表示 interface{}(nil)
type dequeueNil *struct{}
最后,返回 val 之前,将 slot “归零”:*slot = eface{}。
回到 poolChain.popHead(),调用 poolDequeue.popHead() 拿到缓存的对象后,直接返回。否则,将 d 重新指向 d.prev,继续尝试获取缓存的对象。
getSlow
如果在 shared 里没有获取到缓存对象,则继续调用 Pool.getSlow(),尝试从其他 P 的 poolLocal 偷取:
func (p *Pool) getSlow(pid int) interface{} {
// See the comment in pin regarding ordering of the loads.
size := atomic.LoadUintptr(p.localSize) // load-acquire
locals := p.local // load-consume
// Try to steal one element from other procs.
// 从其他 P 中窃取对象
for i := 0; i int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 尝试从victim cache中取对象。这发生在尝试从其他 P 的 poolLocal 偷去失败后,
// 因为这样可以使 victim 中的对象更容易被回收。
size = atomic.LoadUintptr(p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
for i := 0; i int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 清空 victim cache。下次就不用再从这里找了
atomic.StoreUintptr(p.victimSize, 0)
return nil
}
从索引为 pid+1 的 poolLocal 处开始,尝试调用 shared.popTail() 获取缓存对象。如果没有拿到,则从 victim 里找,和 poolLocal 的逻辑类似。
最后,实在没找到,就把 victimSize 置 0,防止后来的“人”再到 victim 里找。
在 Get 函数的最后,经过这一番操作还是没找到缓存的对象,就调用 New 函数创建一个新的对象。
popTail
最后,还剩一个 popTail 函数:
func (c *poolChain) popTail() (interface{}, bool) {
d := loadPoolChainElt(c.tail)
if d == nil {
return nil, false
}
for {
d2 := loadPoolChainElt(d.next)
if val, ok := d.popTail(); ok {
return val, ok
}
if d2 == nil {
// 双向链表只有一个尾节点,现在为空
return nil, false
}
// 双向链表的尾节点里的双端队列被“掏空”,所以继续看下一个节点。
// 并且由于尾节点已经被“掏空”,所以要甩掉它。这样,下次 popHead 就不会再看它有没有缓存对象了。
if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) {
// 甩掉尾节点
storePoolChainElt(d2.prev, nil)
}
d = d2
}
}
在 for 循环的一开始,就把 d.next 加载到了 d2。因为 d 可能会短暂为空,但如果 d2 在 pop 或者 pop fails 之前就不为空的话,说明 d 就会永久为空了。在这种情况下,可以安全地将 d 这个结点“甩掉”。
最后,将 c.tail 更新为 d2,可以防止下次 popTail 的时候查看一个空的 dequeue;而将 d2.prev 设置为 nil,可以防止下次 popHead 时查看一个空的 dequeue。
我们再看一下核心的 poolDequeue.popTail:
// src/sync/poolqueue.go:147
func (d *poolDequeue) popTail() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(d.headTail)
head, tail := d.unpack(ptrs)
// 判断队列是否空
if tail == head {
// Queue is empty.
return nil, false
}
// 先搞定 head 和 tail 指针位置。如果搞定,那么这个 slot 就归属我们了
ptrs2 := d.pack(head, tail+1)
if atomic.CompareAndSwapUint64(d.headTail, ptrs, ptrs2) {
// Success.
slot = d.vals[tailuint32(len(d.vals)-1)]
break
}
}
// We now own slot.
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
slot.val = nil
atomic.StorePointer(slot.typ, nil)
// At this point pushHead owns the slot.
return val, true
}
popTail 从队列尾部移除一个元素,如果队列为空,返回 false。此函数可能同时被多个消费者调用。
函数的核心是一个无限循环,又是一个无锁编程。先解出 head,tail 指针值,如果两者相等,说明队列为空。
因为要从尾部移除一个元素,所以 tail 指针前进 1,然后使用原子操作设置 headTail。
最后,将要移除的 slot 的 val 和 typ “归零”:
slot.val = nil
atomic.StorePointer(slot.typ, nil)
Put
// src/sync/pool.go
// Put 将对象添加到 Pool
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
// ……
l, _ := p.pin()
if l.private == nil {
l.private = x
x = nil
}
if x != nil {
l.shared.pushHead(x)
}
runtime_procUnpin()
//……
}
同样删掉了 race 相关的函数,看起来清爽多了。整个 Put 的逻辑也很清晰:
- 先绑定 g 和 P,然后尝试将 x 赋值给 private 字段。
- 如果失败,就调用
pushHead 方法尝试将其放入 shared 字段所维护的双端队列中。
同样用流程图来展示整个过程:
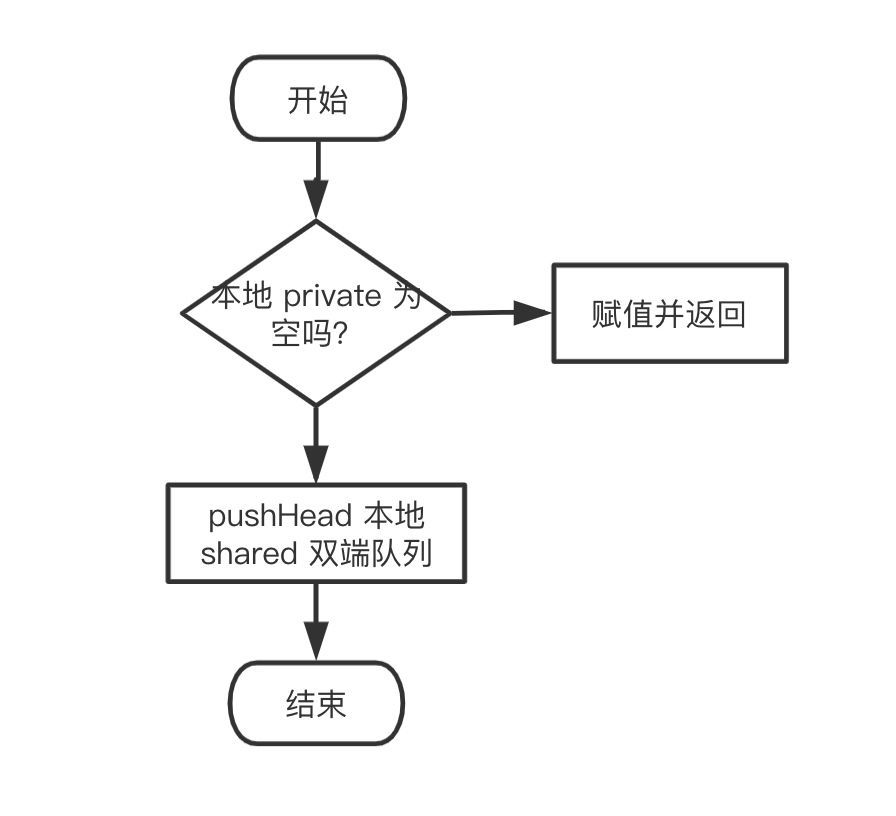
pushHead
我们来看 pushHead 的源码,比较清晰:
// src/sync/poolqueue.go
func (c *poolChain) pushHead(val interface{}) {
d := c.head
if d == nil {
// poolDequeue 初始长度为8
const initSize = 8 // Must be a power of 2
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
storePoolChainElt(c.tail, d)
}
if d.pushHead(val) {
return
}
// 前一个 poolDequeue 长度的 2 倍
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// Can't make it any bigger.
newSize = dequeueLimit
}
// 首尾相连,构成链表
d2 := poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(d.next, d2)
d2.pushHead(val)
}
如果 c.head 为空,就要创建一个 poolChainElt,作为首结点,当然也是尾节点。它管理的双端队列的长度,初始为 8,放满之后,再创建一个 poolChainElt 节点时,双端队列的长度就要翻倍。当然,有一个最大长度限制(2^30):
const dequeueBits = 32
const dequeueLimit = (1 dequeueBits) / 4
调用 poolDequeue.pushHead 尝试将对象放到 poolDeque 里去:
// src/sync/poolqueue.go
// 将 val 添加到双端队列头部。如果队列已满,则返回 false。此函数只能被一个生产者调用
func (d *poolDequeue) pushHead(val interface{}) bool {
ptrs := atomic.LoadUint64(d.headTail)
head, tail := d.unpack(ptrs)
if (tail+uint32(len(d.vals)))(1dequeueBits-1) == head {
// 队列满了
return false
}
slot := d.vals[headuint32(len(d.vals)-1)]
// 检测这个 slot 是否被 popTail 释放
typ := atomic.LoadPointer(slot.typ)
if typ != nil {
// 另一个 groutine 正在 popTail 这个 slot,说明队列仍然是满的
return false
}
// The head slot is free, so we own it.
if val == nil {
val = dequeueNil(nil)
}
// slot占位,将val存入vals中
*(*interface{})(unsafe.Pointer(slot)) = val
// head 增加 1
atomic.AddUint64(d.headTail, 1dequeueBits)
return true
}
首先判断队列是否已满:
if (tail+uint32(len(d.vals)))(1dequeueBits-1) == head {
// Queue is full.
return false
}
也就是将尾部指针加上 d.vals 的长度,再取低 31 位,看它是否和 head 相等。我们知道,d.vals 的长度实际上是固定的,因此如果队列已满,那么 if 语句的两边就是相等的。如果队列满了,直接返回 false。
否则,队列没满,通过 head 指针找到即将填充的 slot 位置:取 head 指针的低 31 位。
// Check if the head slot has been released by popTail.
typ := atomic.LoadPointer(slot.typ)
if typ != nil {
// Another goroutine is still cleaning up the tail, so
// the queue is actually still full.
// popTail 是先设置 val,再将 typ 设置为 nil。设置完 typ 之后,popHead 才可以操作这个 slot
return false
}
上面这一段用来判断是否和 popTail 有冲突发生,如果有,则直接返回 false。
最后,将 val 赋值到 slot,并将 head 指针值加 1。
// slot占位,将val存入vals中
*(*interface{})(unsafe.Pointer(slot)) = val
这里的实现比较巧妙,slot 是 eface 类型,将 slot 转为 interface{} 类型,这样 val 能以 interface{} 赋值给 slot 让 slot.typ 和 slot.val 指向其内存块,于是 slot.typ 和 slot.val 均不为空。
pack/unpack
最后我们再来看一下 pack 和 unpack 函数,它们实际上是一组绑定、解绑 head 和 tail 指针的两个函数。
// src/sync/poolqueue.go
const dequeueBits = 32
func (d *poolDequeue) pack(head, tail uint32) uint64 {
const mask = 1dequeueBits - 1
return (uint64(head) dequeueBits) |
uint64(tailmask)
}
mask 的低 31 位为全 1,其他位为 0,它和 tail 相与,就是只看 tail 的低 31 位。而 head 向左移 32 位之后,低 32 位为全 0。最后把两部分“或”起来,head 和 tail 就“绑定”在一起了。
相应的解绑函数:
func (d *poolDequeue) unpack(ptrs uint64) (head, tail uint32) {
const mask = 1dequeueBits - 1
head = uint32((ptrs >> dequeueBits) mask)
tail = uint32(ptrs mask)
return
}
取出 head 指针的方法就是将 ptrs 右移 32 位,再与 mask 相与,同样只看 head 的低 31 位。而 tail 实际上更简单,直接将 ptrs 与 mask 相与就可以了。
GC
对于 Pool 而言,并不能无限扩展,否则对象占用内存太多了,会引起内存溢出。
几乎所有的池技术中,都会在某个时刻清空或清除部分缓存对象,那么在 Go 中何时清理未使用的对象呢?
答案是 GC 发生时。
在 pool.go 文件的 init 函数里,注册了 GC 发生时,如何清理 Pool 的函数:
// src/sync/pool.go
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
编译器在背后做了一些动作:
// src/runtime/mgc.go
// Hooks for other packages
var poolcleanup func()
// 利用编译器标志将 sync 包中的清理注册到运行时
//go:linkname sync_runtime_registerPoolCleanup sync.runtime_registerPoolCleanup
func sync_runtime_registerPoolCleanup(f func()) {
poolcleanup = f
}
具体来看下:
func poolCleanup() {
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
oldPools, allPools = allPools, nil
}
poolCleanup 会在 STW 阶段被调用。整体看起来,比较简洁。主要是将 local 和 victim 作交换,这样也就不致于让 GC 把所有的 Pool 都清空了,有 victim 在“兜底”。
如果 sync.Pool 的获取、释放速度稳定,那么就不会有新的池对象进行分配。如果获取的速度下降了,那么对象可能会在两个 GC 周期内被释放,而不是以前的一个 GC 周期。
鸟窝的【Go 1.13中 sync.Pool 是如何优化的?】讲了 1.13 中的优化。
参考资料【理解 Go 1.13 中 sync.Pool 的设计与实现】 手动模拟了一下调用 poolCleanup 函数前后 oldPools,allPools,p.vitcim 的变化过程,很精彩:
初始状态下,oldPools 和 allPools 均为 nil。
第 1 次调用 Get,由于 p.local 为 nil,将会在 pinSlow 中创建 p.local,然后将 p 放入 allPools,此时 allPools 长度为 1,oldPools 为 nil。对象使用完毕,第 1 次调用 Put 放回对象。第 1 次GC STW 阶段,allPools 中所有 p.local 将值赋值给 victim 并置为 nil。allPools 赋值给 oldPools,最后 allPools 为 nil,oldPools 长度为 1。第 2 次调用 Get,由于 p.local 为 nil,此时会从 p.victim 里面尝试取对象。对象使用完毕,第 2 次调用 Put 放回对象,但由于 p.local 为 nil,重新创建 p.local,并将对象放回,此时 allPools 长度为 1,oldPools 长度为 1。第 2 次 GC STW 阶段,oldPools 中所有 p.victim 置 nil,前一次的 cache 在本次 GC 时被回收,allPools 所有 p.local 将值赋值给 victim 并置为nil,最后 allPools 为 nil,oldPools 长度为 1。
我根据这个流程画了一张图,可以理解地更清晰一些:
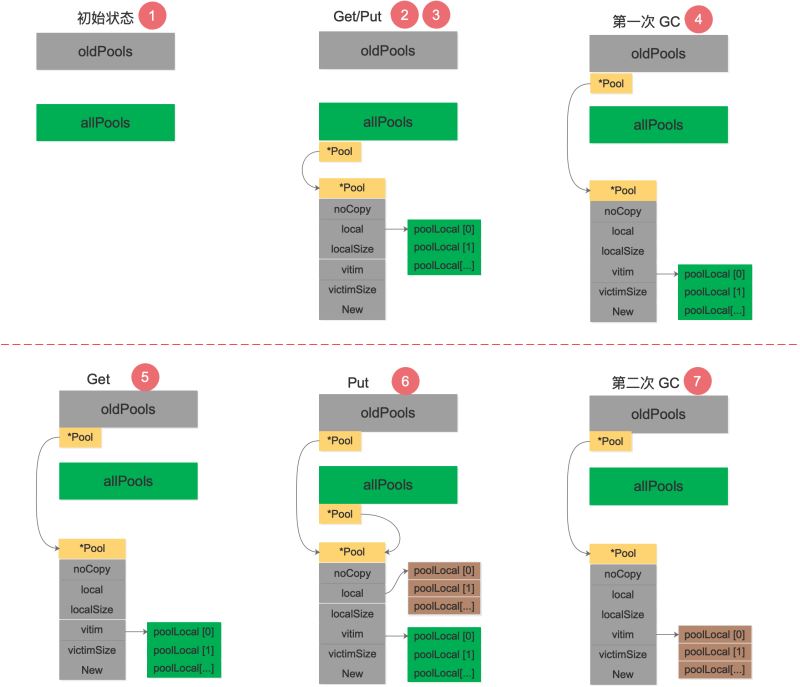
需要指出的是,allPools 和 oldPools 都是切片,切片的元素是指向 Pool 的指针,Get/Put 操作不需要通过它们。在第 6 步,如果还有其他 Pool 执行了 Put 操作,allPools 这时就会有多个元素。
在 Go 1.13 之前的实现中,poolCleanup 比较“简单粗暴”:
func poolCleanup() {
for i, p := range allPools {
allPools[i] = nil
for i := 0; i int(p.localSize); i++ {
l := indexLocal(p.local, i)
l.private = nil
for j := range l.shared {
l.shared[j] = nil
}
l.shared = nil
}
p.local = nil
p.localSize = 0
}
allPools = []*Pool{}
}
直接清空了所有 Pool 的 p.local 和 poolLocal.shared。
通过两者的对比发现,新版的实现相比 Go 1.13 之前,GC 的粒度拉大了,由于实际回收的时间线拉长,单位时间内 GC 的开销减小。
由此基本明白 p.victim 的作用。它的定位是次级缓存,GC 时将对象放入其中,下一次 GC 来临之前如果有 Get 调用则会从 p.victim 中取,直到再一次 GC 来临时回收。
同时由于从 p.victim 中取出对象使用完毕之后并未放回 p.victim 中,在一定程度也减小了下一次 GC 的开销。原来 1 次 GC 的开销被拉长到 2 次且会有一定程度的开销减小,这就是 p.victim 引入的意图。
【理解 Go 1.13 中 sync.Pool 的设计与实现】 这篇文章最后还总结了 sync.Pool 的设计理念,包括:无锁、操作对象隔离、原子操作代替锁、行为隔离——链表、Victim Cache 降低 GC 开销。写得非常不错,推荐阅读。
另外,关于 sync.Pool 中锁竞争优化的文章,推荐阅读芮大神的【优化锁竞争】。
总结
本文先是介绍了 Pool 是什么,有什么作用,接着给出了 Pool 的用法以及在标准库、一些第三方库中的用法,还介绍了 pool_test 中的一些测试用例。最后,详细解读了 sync.Pool 的源码。
本文的结尾部分,再来详细地总结一下关于 sync.Pool 的要点:
- 关键思想是对象的复用,避免重复创建、销毁。将暂时不用的对象缓存起来,待下次需要的时候直接使用,不用再次经过内存分配,复用对象的内存,减轻 GC 的压力。
sync.Pool 是协程安全的,使用起来非常方便。设置好 New 函数后,调用 Get 获取,调用 Put 归还对象。- Go 语言内置的 fmt 包,encoding/json 包都可以看到 sync.Pool 的身影;
gin,Echo 等框架也都使用了 sync.Pool。
- 不要对 Get 得到的对象有任何假设,更好的做法是归还对象时,将对象“清空”。
- Pool 里对象的生命周期受 GC 影响,不适合于做连接池,因为连接池需要自己管理对象的生命周期。
- Pool 不可以指定⼤⼩,⼤⼩只受制于 GC 临界值。
procPin 将 G 和 P 绑定,防止 G 被抢占。在绑定期间,GC 无法清理缓存的对象。- 在加入
victim 机制前,sync.Pool 里对象的最⼤缓存时间是一个 GC 周期,当 GC 开始时,没有被引⽤的对象都会被清理掉;加入 victim 机制后,最大缓存时间为两个 GC 周期。
- Victim Cache 本来是计算机架构里面的一个概念,是 CPU 硬件处理缓存的一种技术,
sync.Pool 引入的意图在于降低 GC 压力的同时提高命中率。
sync.Pool 的最底层使用切片加链表来实现双端队列,并将缓存的对象存储在切片中。
参考资料
【欧神 源码分析】https://changkun.us/archives/2018/09/256/
【Go 夜读】https://reading.hidevops.io/reading/20180817/2018-08-17-sync-pool-reading.pdf
【夜读第 14 期视频】https://www.youtube.com/watch?v=jaepwn2PWPklist=PLe5svQwVF1L5bNxB0smO8gNfAZQYWdIpI
【源码分析,伪共享】https://juejin.im/post/5d4087276fb9a06adb7fbe4a
【golang的对象池sync.pool源码解读】https://zhuanlan.zhihu.com/p/99710992
【理解 Go 1.13 中 sync.Pool 的设计与实现】https://zhuanlan.zhihu.com/p/110140126
【优缺点,图】http://cbsheng.github.io/posts/golang标准库sync.pool原理及源码简析/
【xiaorui 优化锁竞争】http://xiaorui.cc/archives/5878
【性能优化之路,自定义多种规格的缓存】https://blog.cyeam.com/golang/2017/02/08/go-optimize-slice-pool
【sync.Pool 有什么缺点】https://mp.weixin.qq.com/s?__biz=MzA4ODg0NDkzOA==mid=2247487149idx=1sn=f38f2d72fd7112e19e97d5a2cd304430source=41
【1.12 和 1.13 的演变】https://github.com/watermelo/dailyTrans/blob/master/golang/sync_pool_understand.md
【董泽润 演进】https://www.jianshu.com/p/2e08332481c5
【noCopy】https://github.com/golang/go/issues/8005
【董泽润 cpu cache】https://www.jianshu.com/p/dc4b5562aad2
【gomemcache 例子】https://docs.kilvn.com/The-Golang-Standard-Library-by-Example/chapter16/16.01.html
【鸟窝 1.13 优化】https://colobu.com/2019/10/08/how-is-sync-Pool-improved-in-Go-1-13/
【A journey with go】https://medium.com/a-journey-with-go/go-understand-the-design-of-sync-pool-2dde3024e277
【封装了一个计数组件】https://www.akshaydeo.com/blog/2017/12/23/How-did-I-improve-latency-by-700-percent-using-syncPool/
【伪共享】http://ifeve.com/falsesharing/
到此这篇关于深度解密 Go 语言之 sync.Pool的文章就介绍到这了,更多相关go sync.pool内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- go语言中int和byte转换方式
- Go语言中的字符串处理方法示例详解
- Go语言的http/2服务器功能及客户端使用
