在工作中处理excel遇到需要根据器件生产供应商全称填写简称的一列,由于数据表格中器件数多达几万条,单纯靠excel筛选功能手动处理需要耗费大量时间,这里使用Python中的pandas模块,读取excel进行处理。
1、需求
根据存储有供应商全称简称对应的表格对应关系.xlsx,自动填写带有供应商全称的表格待处理文件.xlsx中简称的一列。

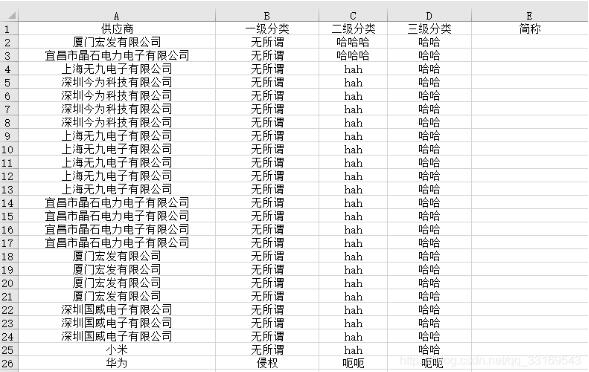
2.脚本思路
首先使用pandas读取第一个表格对应关系.xlsx,然后将其储存在一个字典中,字典的键为供应商的全称,字典的值为供应商的简称。
然后读取第二个表格待处理文件.xlsx,根据列的标题头,找到供应商全称所处在的列,根据这一列每一个供应商的全称查询字典中对应键的值,将其写入表格中对应行的简称处。(这里暂时假设对应关系和待处理文件中供应商的全称如果是同一家公司则公司全称是一模一样的,存在些许差别的处理的方法在下一篇文章中在记录)。
3.代码
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 4 21:25:05 2021
@author: ruofei
"""
import pandas as pd
#填写待处理文件和对应关系的excel文件路径
#注意:脚本运行时需保证被使用excel文件处于关闭状态
file1 = r'待处理文件.xlsx'
file2 = r'对应关系.xlsx'
#填写待处理文件中 全称所在的列名和简称要放置的列名
qc1="供应商"
jc1="简称"
#填写对应关系中 全称所在的列数和简称所在的列数
qc2="全称"
jc2="简称"
#填写读取excel文件的sheet表名
sheet1="Sheet1"
sheet2="Sheet1"
#--------------------*-------------*--------------*---------------------
#--------------------*-------------*--------------*---------------------
data1 = pd.read_excel(file1, sheet_name = sheet1)
data2 = pd.read_excel(file2, sheet_name = sheet2)
#print("输出表格所有")
#print(data1)
row1 = data1.shape[0]#行数
col1=data1.shape[1]#列数
row2 = data2.shape[0]#行数
col2=data2.shape[1]#
#print("表格文件有"+str(row1)+"行,"+str(col1)+"列")
duiying=dict()
#生成对应关系的字典
for i in range(row2):
quancheng=data2.loc[i,qc2]
jiancheng=data2.loc[i,jc2]
duiying[quancheng]=jiancheng
#print(quancheng)
#company1=data1.loc[0][0]
#company2=data1.loc[1][0]
#print("公司一为"+str(company1)+"\n"+"公司二为"+str(company2))
for i in range(row1):
a=data1.loc[i,qc1]
#[qc1-1]
#print(str(a))
jiancheng=duiying.get(a)
if a in duiying.keys():
#print(jiancheng)
data1.loc[i,jc1]=jiancheng
else:
#此处修改没有简称赋予值,若赋予全称值则=a,若为空则=" "
data1.loc[i,jc1]=a
data1.to_excel('处理好的文件.xlsx',sheet_name='Sheet1')
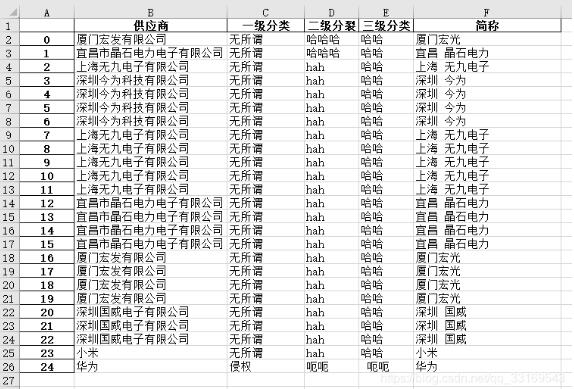
4.实现功能
根据预先整理好的对应关系表格自动填写了表格中简称空白的一列,如果表格中存在对应关系中不存在的公司,则在相应的简称位置填写其全称本身。如下图中,由于表中的小米华为没有给出其简称,因此原样照填。
5.存在问题
在实际应用中处理几万条数据时,绝大部分正常,存在问题是,比如对应关系中全称为(中国)茅台公司,而在要处理的文件中不存在括号,或者括号中英文不同,或者括号中空格数不同,都会在后面读取为不同的字符串,在查询字典中显示不存在。处理方式在下篇中解决。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
您可能感兴趣的文章:- Python应用实现处理excel数据过程解析
- Python利用pandas处理Excel数据的应用详解
- Python Excel处理库openpyxl详解
- 教你怎么用Python处理excel实现自动化办公
- 使用python对excel表格处理的一些小功能
- 如何用python处理excel表格
- python操作openpyxl导出Excel 设置单元格格式及合并处理代码实例
- Python Excel处理库openpyxl使用详解
- 教你用Python实现Excel表格处理
