例如,爬取赵丽颖,赵本山,赵文卓,赵欢,赵日天的图片分别保存在赵丽颖,赵本山,赵文卓,赵欢,赵日天命名的文件夹中,
测试代码
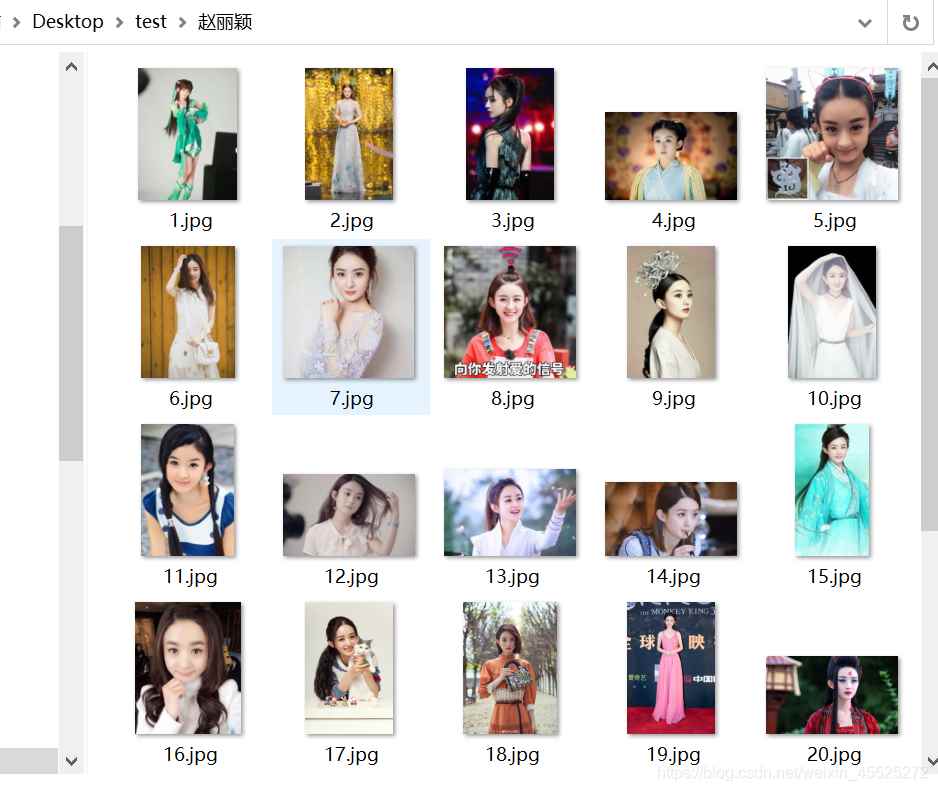
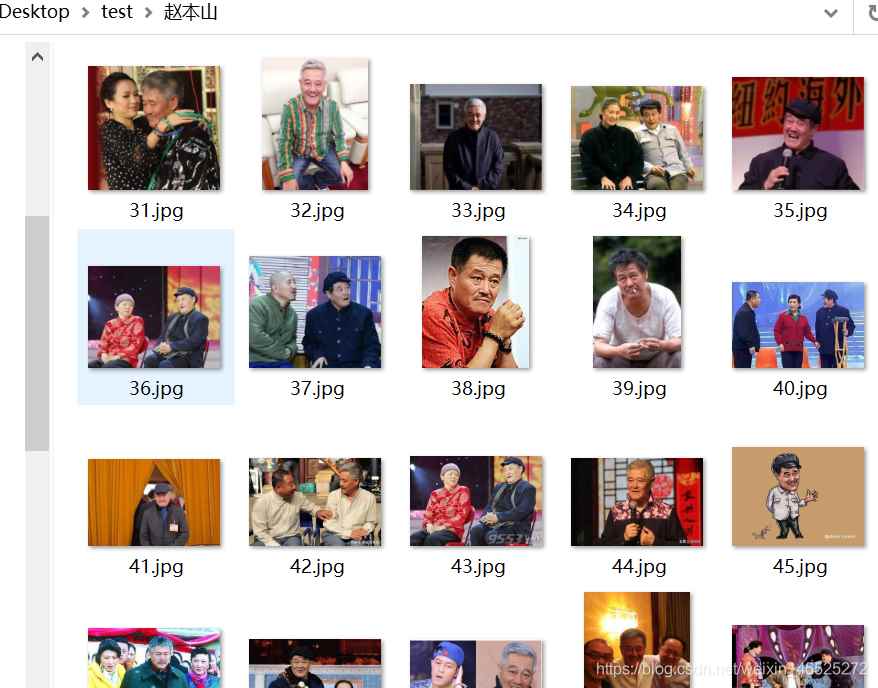
别的图就不放了
import requests
import time
import os
# 请求头,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
# keyword = '云斑白条天牛' # 关键字
keywords = ['赵丽颖','赵本山','赵文卓','赵欢','赵日天']
max_page = 2
i=1 # 记录图片数
for keyword in keywords:
os.makedirs(keyword)
for page in range(1,max_page):
page = page*30
# 网址
url = 'https://image.baidu.com/search/acjson?tn=resultjson_comipn=rjct=201326592is=fp=resultqueryWord='\
+keyword+'cl=2lm=-1ie=utf-8oe=utf-8adpicid=st=-1z=ic=0hd=latest=copyright=word='\
+keyword+'s=se=tab=width=height=face=0istype=2qc=nc=1fr=expermode=force=cg=wallpaperpn='\
+str(page)+'rn=30gsm=1e1596899786625='
# 请求响应
response = requests.get(url=url,headers=headers)
# 得到相应的json数据
json = response.json()
if json.get('data'):
for item in json.get('data')[:30]:
# 图片地址
img_url = item.get('thumbURL')
# 获取图片
image = requests.get(url=img_url)
# 下载图片
newstr = './'+keyword+'/'+str(i)+'.jpg'
# with open('./%s/%d.jpg'%keywords ,%i,'wb') as f:
with open(newstr,'wb') as f:
f.write(image.content) # 图片二进制数据
time.sleep(1) # 等待1s
print('第%d张%s图片下载完成...'%(i,keyword))
i+=1
print('End!')
你要修改的参数
将你想要爬的数据填入keywords 数组中即可
# 这里放你要查询的数组
keywords = ['','','',']
max_page是爬取百度图片的页数,一页是30张,这里写2的话就能爬30张,3能爬60张,以此类推
你要的代码
代码如下:
import requests
import time
import os
# 请求头,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
# 这里放你要查询的数组
keywords = ['','','',']
max_page = 4
i=1 # 记录图片数
for keyword in keywords:
os.makedirs(keyword)
for page in range(1,max_page):
page = page*30
# 网址
url = 'https://image.baidu.com/search/acjson?tn=resultjson_comipn=rjct=201326592is=fp=resultqueryWord='\
+keyword+'cl=2lm=-1ie=utf-8oe=utf-8adpicid=st=-1z=ic=0hd=latest=copyright=word='\
+keyword+'s=se=tab=width=height=face=0istype=2qc=nc=1fr=expermode=force=cg=wallpaperpn='\
+str(page)+'rn=30gsm=1e1596899786625='
# 请求响应
response = requests.get(url=url,headers=headers)
# 得到相应的json数据
json = response.json()
if json.get('data'):
for item in json.get('data')[:30]:
# 图片地址
img_url = item.get('thumbURL')
# 获取图片
image = requests.get(url=img_url)
# 下载图片
newstr = './'+keyword+'/'+str(i)+'.jpg'
# with open('./%s/%d.jpg'%keywords ,%i,'wb') as f:
with open(newstr,'wb') as f:
f.write(image.content) # 图片二进制数据
time.sleep(1) # 等待1s
print('第%d张%s图片下载完成...'%(i,keyword))
i+=1
print('End!')
到此这篇关于python爬不同图片分别保存在不同文件夹中的实现的文章就介绍到这了,更多相关python爬图片保存不同文件夹内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- Python爬取网站图片并保存的实现示例
- Python 爬虫批量爬取网页图片保存到本地的实现代码
- Python3直接爬取图片URL并保存示例
- Python使用爬虫抓取美女图片并保存到本地的方法【测试可用】
- Python爬虫获取图片并下载保存至本地的实例
- Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
