写在前面
QQ群里偶然看到群友问这个问题, pandas读取大文件时怎么才能获取进度? 我第一反应是: 除非pandas的read_excel等函数提供了回调函数的接口, 否则应该没办法做到. 搜索了一下官方文档和网上的帖子, 果然是没有现成的方案, 只能自己动手.
准备工作
确定方案
一开始我就确认了实现方案, 那就是增加回调函数. 这里现学现卖科普一下什么是回调函数. 简单的说就是:
所使用的模块里面, 会调用一个你给定的外部方法/函数, 就是回调函数. 拿本次的尝试作为例子, 我会编写一个"显示进度函数", 通过传参的方式传入pd.read_excel, 这样pd在读取excel时, 会边读取边调用"显示进度函数". 为什么不直接在pd里面增加? 因为pd读取excel文件时是阻塞的, 内部方法在被调用时无法抛出进度信息. (如有谬误请指正)
理解读取方式
先得了解一下pandas是怎么读取excel的. 在pycharm里面按住control点击read_excel, 再浏览一下代码根据关键的函数继续跳转, 还是挺容易得到调用的路径的.
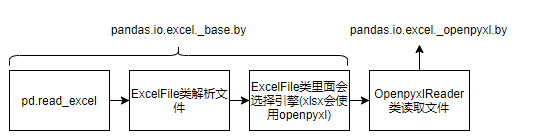
最后OpenpyxlReader读取excel的方法代码如下. 很明显重点就在其中的for循环里. 调用get_sheet_data时, 已经通过一系列方法获得了目标sheet(这里细节不赘述), 然后在for循环里逐行读取数据并返回data最后生成dataframe.
def get_sheet_data(self, sheet, convert_float: bool) -> List[List[Scalar]]:
# GH 39001
# Reading of excel file depends on dimension data being correct but
# writers sometimes omit or get it wrong
import openpyxl
version = LooseVersion(get_version(openpyxl))
# There is no good way of determining if a sheet is read-only
# https://foss.heptapod.net/openpyxl/openpyxl/-/issues/1605
is_readonly = hasattr(sheet, "reset_dimensions")
if version >= "3.0.0" and is_readonly:
sheet.reset_dimensions()
data: List[List[Scalar]] = []
last_row_with_data = -1
for row_number, row in enumerate(sheet.rows):
converted_row = [self._convert_cell(cell, convert_float) for cell in row]
if not all(cell == "" for cell in converted_row):
last_row_with_data = row_number
data.append(converted_row)
# Trim trailing empty rows
data = data[: last_row_with_data + 1]
if version >= "3.0.0" and is_readonly and len(data) > 0:
# With dimension reset, openpyxl no longer pads rows
max_width = max(len(data_row) for data_row in data)
if min(len(data_row) for data_row in data) max_width:
empty_cell: List[Scalar] = [""]
data = [
data_row + (max_width - len(data_row)) * empty_cell
for data_row in data
]
return data
开始改动
这里直接暴力更改pandas库源文件!(仅用于调试, 注意备份和保护自己的工作环境)
主程序代码
编写main.py, 代码比较简单, 相关功能我都用注释作为解释. 其中show_pd_read_excel_progress就是我编写的回调函数, 通过命令行的方式输出实时的读取进度. 当然你如果编写的是GUI程序比如PYQT5, 也可以在这个回调函数中发送signal给main UI, 做成progress bar或者其他的GUI样式.
import pandas as pd
from datetime import datetime
'''
定义回调函数
cur: 读取时的当前行数
tt: 读取文件的总行数
'''
def show_pd_read_excel_progress(cur, tt):
# 进度数值
progress = " {:.2f}%".format(cur/tt*100)
# 进度条
bar = " ".join("█" for _ in range(int(cur/tt*100/10)))
# 显示进度
print("\r进度:" + bar + progress, end="", flush=True)
# 记录开始时间
t = datetime.now()
# 开始读取excel
print("pd.read_excel: test_4.xlsx...")
xl_data = pd.read_excel("test_4.xlsx", callback=show_pd_read_excel_progress)
# 打印excel头几行
print(xl_data.head())
print("\n")
# 显示花费的时间
print("Time spent:", datetime.now()-t)
修改pandas源码
再自己观察一下, 我在pd.read_excel方法的参数里增加了callback参数, 这个参数是原版read_excel方法里没有的. 所以我们需要处理pandas源码, 这个源码在…/pandas/io/excel/_base.py中, pycharm中按住control点击read_excel可以快速跳转. 这个地方我增加了一个参数callback, 默认值为None. 下方io.parse同样把callback参数传递给ExcelFile类.
def read_excel(
io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=False,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
comment=None,
skipfooter=0,
convert_float=True,
mangle_dupe_cols=True,
storage_options: StorageOptions = None,
callback = None, # 增加callback参数
):
should_close = False
if not isinstance(io, ExcelFile):
should_close = True
io = ExcelFile(io, storage_options=storage_options, engine=engine)
elif engine and engine != io.engine:
raise ValueError(
"Engine should not be specified when passing "
"an ExcelFile - ExcelFile already has the engine set"
)
try:
data = io.parse(
sheet_name=sheet_name,
header=header,
names=names,
index_col=index_col,
usecols=usecols,
squeeze=squeeze,
dtype=dtype,
converters=converters,
true_values=true_values,
false_values=false_values,
skiprows=skiprows,
nrows=nrows,
na_values=na_values,
keep_default_na=keep_default_na,
na_filter=na_filter,
verbose=verbose,
parse_dates=parse_dates,
date_parser=date_parser,
thousands=thousands,
comment=comment,
skipfooter=skipfooter,
convert_float=convert_float,
mangle_dupe_cols=mangle_dupe_cols,
callback = callback, # 增加callback参数
)
finally:
# make sure to close opened file handles
if should_close:
io.close()
return data
... # 省略代码
浏览一下ExcelFile类(还在_base.py中)的代码, 这个类会根据文件类型选择引擎, 我读取的是xlsx文件, 所以会跳转到openpyxl并把所有的参数传递过去, 这个类不用处理. 下面跳转到_openpyxl.py中看一下OpenpyxlReader类, 这个类是继承BaseExcelReader类(在_base.py中)的, 所以还是得回去看一下BaseExcelReader, 并修改一下参数, 增加callback(如下2处).
def parse(
self,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=False,
dtype=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
comment=None,
skipfooter=0,
convert_float=True,
mangle_dupe_cols=True,
callback = None, # 增加callback参数
**kwds,
):
... # 省略代码
for asheetname in sheets:
if verbose:
print(f"Reading sheet {asheetname}")
if isinstance(asheetname, str):
sheet = self.get_sheet_by_name(asheetname)
else: # assume an integer if not a string
sheet = self.get_sheet_by_index(asheetname)
data = self.get_sheet_data(sheet, convert_float, callback) # 传递callback参数给get_sheet_data方法
usecols = maybe_convert_usecols(usecols)
... # 省略代码
好了, 终于到重点了, 我们跳转到get_sheet_data方法, 并做对应修改(方法参数, 获取总行数, 调用回调函数). 思路非常清晰, 通过一顿操作, 终于千里迢迢把callback给一层层传递过来了, 所以在一行行读取excel时, 可以调用并显示进度了.
def get_sheet_data(self, sheet, convert_float: bool, callback) -> List[List[Scalar]]: # 传递参数增加callback
# GH 39001
# Reading of excel file depends on dimension data being correct but
# writers sometimes omit or get it wrong
import openpyxl
# 获取sheet的总行数
max_row = sheet.max_row
print("sheet_max_row:", sheet.max_row)
version = LooseVersion(get_version(openpyxl))
# There is no good way of determining if a sheet is read-only
# https://foss.heptapod.net/openpyxl/openpyxl/-/issues/1605
is_readonly = hasattr(sheet, "reset_dimensions")
if version >= "3.0.0" and is_readonly:
sheet.reset_dimensions()
data: List[List[Scalar]] = []
last_row_with_data = -1
for row_number, row in enumerate(sheet.rows):
# 调用回调函数
if callback is not None:
callback(row_number+1, max_row)
converted_row = [self._convert_cell(cell, convert_float) for cell in row]
if not all(cell == "" for cell in converted_row):
last_row_with_data = row_number
data.append(converted_row)
# Trim trailing empty rows
data = data[: last_row_with_data + 1]
if version >= "3.0.0" and is_readonly and len(data) > 0:
# With dimension reset, openpyxl no longer pads rows
max_width = max(len(data_row) for data_row in data)
if min(len(data_row) for data_row in data) max_width:
empty_cell: List[Scalar] = [""]
data = [
data_row + (max_width - len(data_row)) * empty_cell
for data_row in data
]
return data
运行测试
运行一下main.py, 效果如下, 实时显示进度功能已经实现, 且会计算出读取所花费的时间. 如果你是要读取csv或者sql之类的, 也可以照猫画虎.
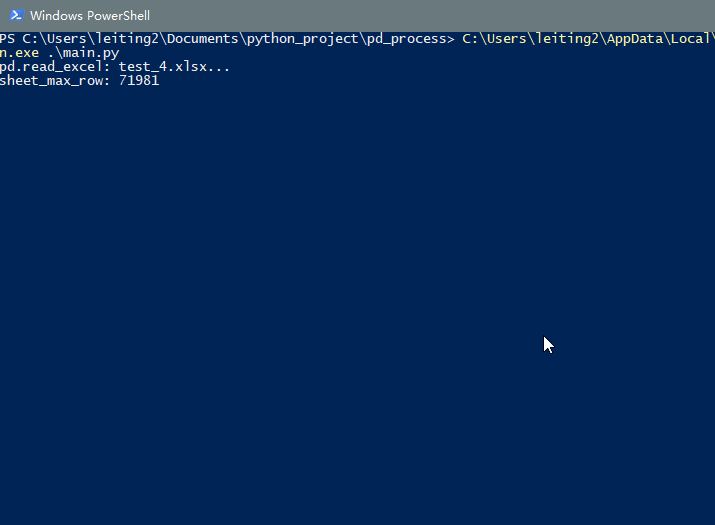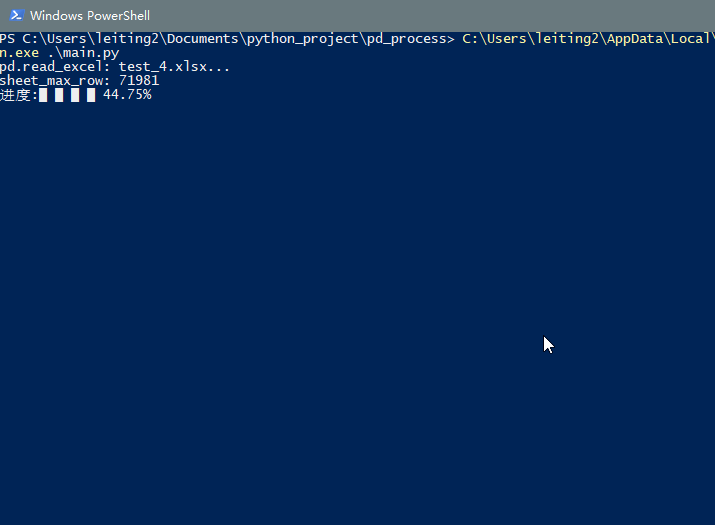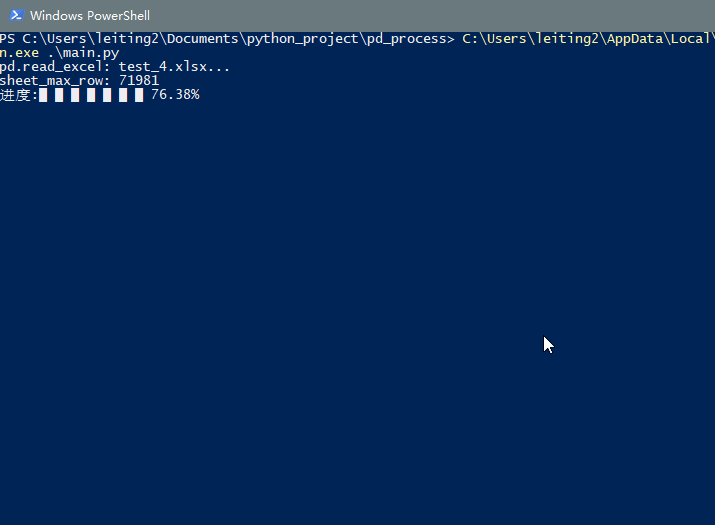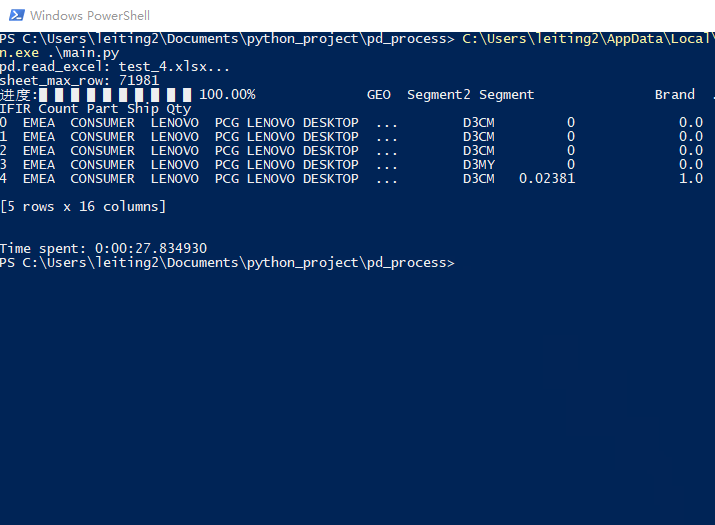
优化和应用
- 前面也说过直接修改pandas源码是非常不科学的操作, 这会破坏已有的编程环境, 且源码换到别的机器上还得重新在修改一遍
- 也尝试过用继承+重写pandas, 不过水平有限没有成功, 希望大家指点
- 实测print进度条会非常费时间, 当然也不需要每读一行excel都更新一次进度条, 定时(比如每秒刷一次)或者定量(每n行, 或者每1%进度刷新一次)比较合理
- 读取大规模数据时, 频繁调用回调函数肯定会耽误效率, 不过如果是GUI程序或者给其他人使用的, 有实时进度肯定会改善用户体验, 其中优劣需要coder自己权衡
到此这篇关于pandas读取excel时获取读取进度的实现的文章就介绍到这了,更多相关pandas读取excel读取内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- 教你使用Pandas直接核算Excel中的快递费用
- Python入门之使用pandas分析excel数据
- pandas快速处理Excel,替换Nan,转字典的操作
- pandas读取excel,txt,csv,pkl文件等命令的操作
- python pandas模糊匹配 读取Excel后 获取指定指标的操作
- pandas针对excel处理的实现
- 关于Python 解决Python3.9 pandas.read_excel(‘xxx.xlsx‘)报错的问题
- 解决使用Pandas 读取超过65536行的Excel文件问题
- 利用Python pandas对Excel进行合并的方法示例
- Python pandas对excel的操作实现示例
- pandas to_excel 添加颜色操作
- 解决python pandas读取excel中多个不同sheet表格存在的问题
- Python pandas如何向excel添加数据
- pandas中的ExcelWriter和ExcelFile的实现方法
- pandas实现excel中的数据透视表和Vlookup函数功能代码
- Python使用Pandas读写Excel实例解析
- pandas将多个dataframe以多个sheet的形式保存到一个excel文件中
- 利用python Pandas实现批量拆分Excel与合并Excel
