# !/usr/bin/nev python
# -*-coding:utf8-*-
import requests, os, csv
from pprint import pprint
from lxml import etree
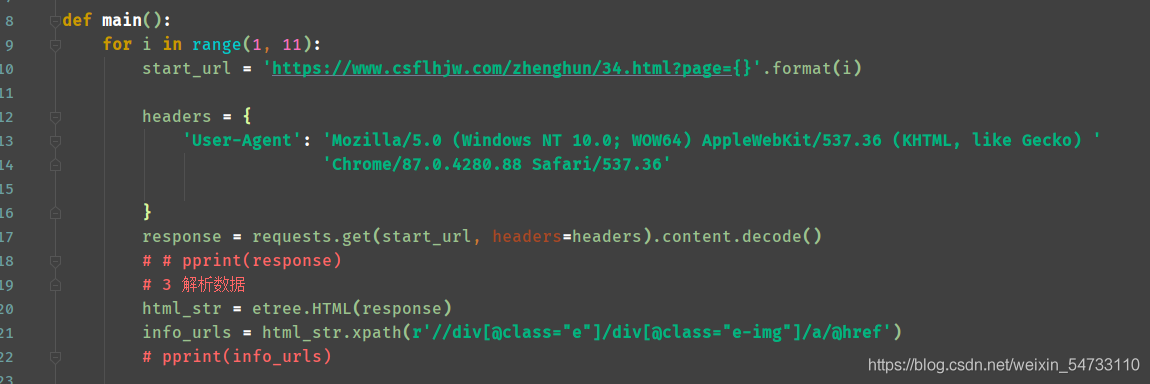
def main():
for i in range(1, 11):
start_url = 'https://www.csflhjw.com/zhenghun/34.html?page={}'.format(i)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(start_url, headers=headers).content.decode()
# # pprint(response)
# 3 解析数据
html_str = etree.HTML(response)
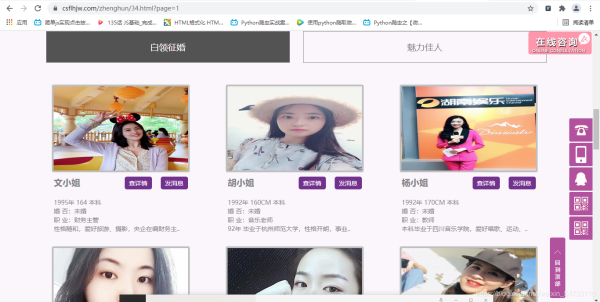
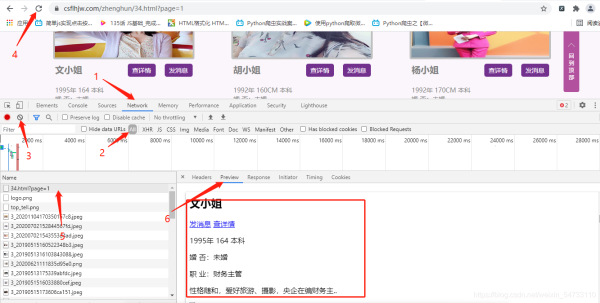
info_urls = html_str.xpath(r'//div[@class="e"]/div[@class="e-img"]/a/@href')
# pprint(info_urls)
# 4、循环遍历 构造img_info_url
for info_url in info_urls:
info_url = r'https://www.csflhjw.com' + info_url
# print(info_url)
# 5、对info_url发请求,解析得到img_urls
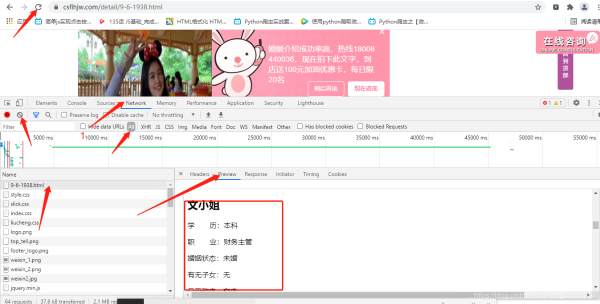
response = requests.get(info_url, headers=headers).content.decode()
html_str = etree.HTML(response)
# pprint(html_str)
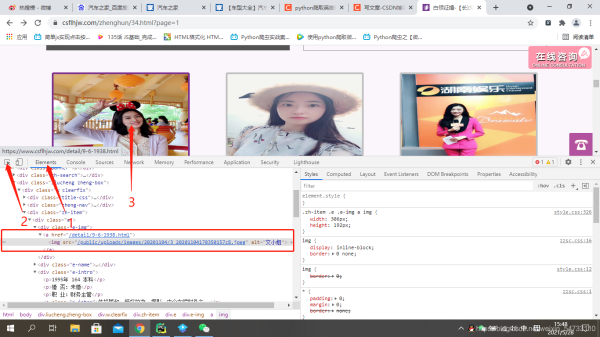
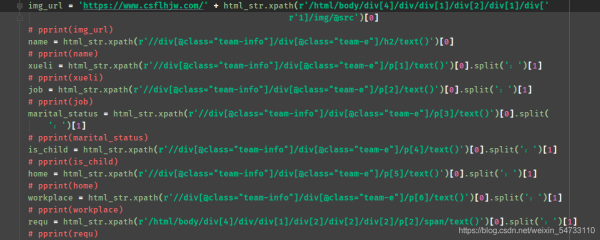
img_url = 'https://www.csflhjw.com/' + html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[1]/div['
r'1]/img/@src')[0]
# pprint(img_url)
name = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/h2/text()')[0]
# pprint(name)
xueli = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[1]/text()')[0].split(':')[1]
# pprint(xueli)
job = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[2]/text()')[0].split(':')[1]
# pprint(job)
marital_status = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[3]/text()')[0].split(
':')[1]
# pprint(marital_status)
is_child = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[4]/text()')[0].split(':')[1]
# pprint(is_child)
home = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[5]/text()')[0].split(':')[1]
# pprint(home)
workplace = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[6]/text()')[0].split(':')[1]
# pprint(workplace)
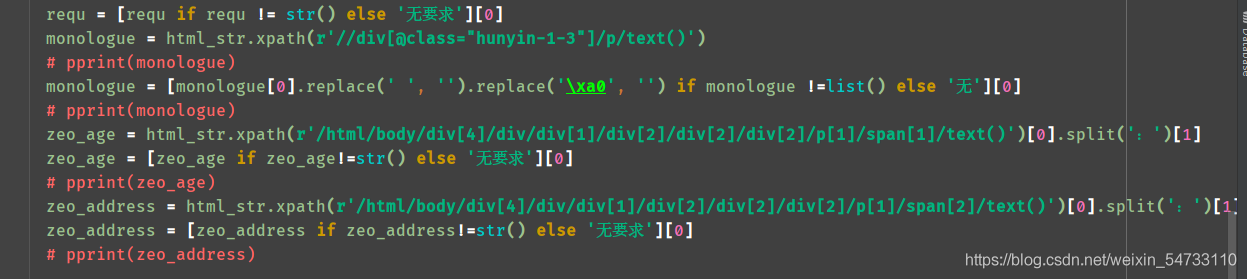
requ = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[2]/span/text()')[0].split(':')[1]
# pprint(requ)
requ = [requ if requ != str() else '无要求'][0]
monologue = html_str.xpath(r'//div[@class="hunyin-1-3"]/p/text()')
# pprint(monologue)
monologue = [monologue[0].replace(' ', '').replace('\xa0', '') if monologue !=list() else '无'][0]
# pprint(monologue)
zeo_age = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[1]/span[1]/text()')[0].split(':')[1]
zeo_age = [zeo_age if zeo_age!=str() else '无要求'][0]
# pprint(zeo_age)
zeo_address = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[1]/span[2]/text()')[0].split(':')[1]
zeo_address = [zeo_address if zeo_address!=str() else '无要求'][0]
# pprint(zeo_address)
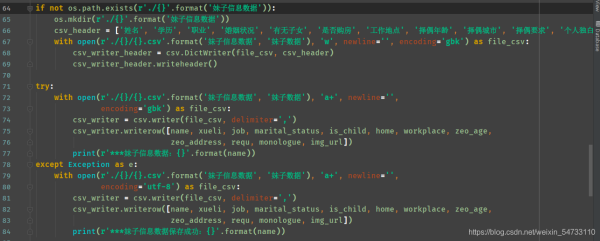
if not os.path.exists(r'./{}'.format('妹子信息数据')):
os.mkdir(r'./{}'.format('妹子信息数据'))
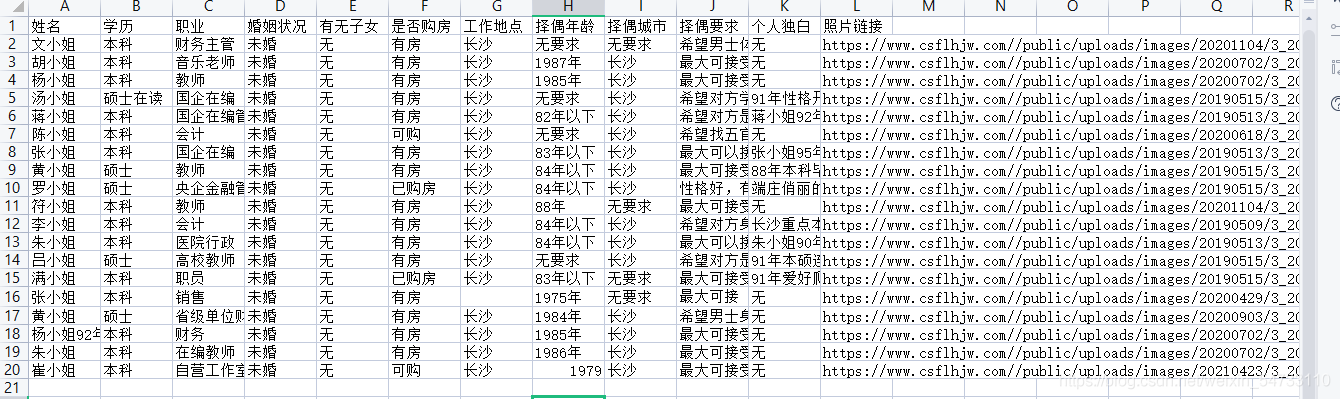
csv_header = ['姓名', '学历', '职业', '婚姻状况', '有无子女', '是否购房', '工作地点', '择偶年龄', '择偶城市', '择偶要求', '个人独白', '照片链接']
with open(r'./{}/{}.csv'.format('妹子信息数据', '妹子数据'), 'w', newline='', encoding='gbk') as file_csv:
csv_writer_header = csv.DictWriter(file_csv, csv_header)
csv_writer_header.writeheader()
try:
with open(r'./{}/{}.csv'.format('妹子信息数据', '妹子数据'), 'a+', newline='',
encoding='gbk') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, xueli, job, marital_status, is_child, home, workplace, zeo_age,
zeo_address, requ, monologue, img_url])
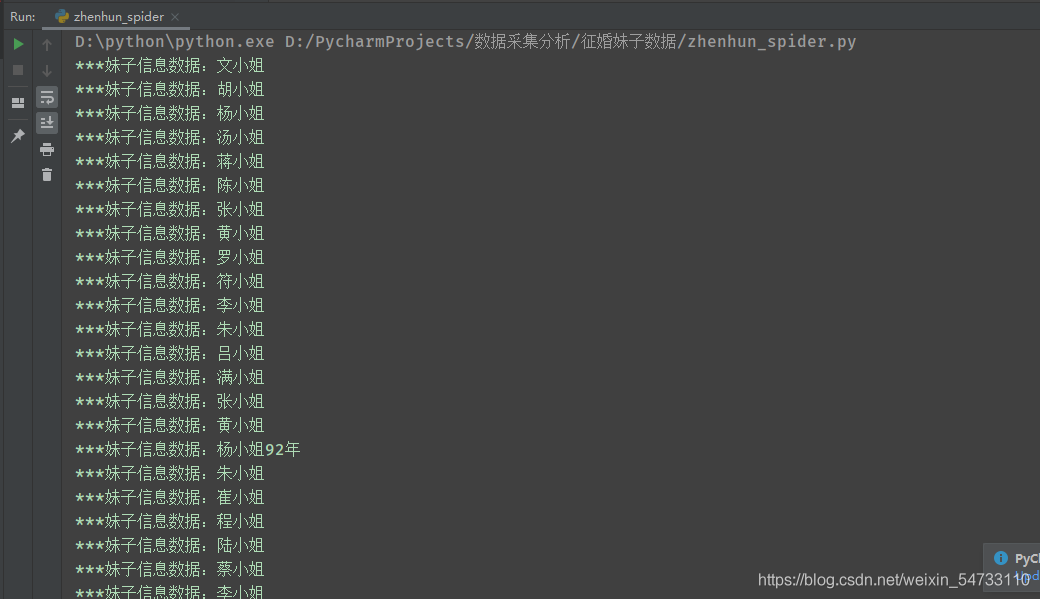
print(r'***妹子信息数据:{}'.format(name))
except Exception as e:
with open(r'./{}/{}.csv'.format('妹子信息数据', '妹子数据'), 'a+', newline='',
encoding='utf-8') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, xueli, job, marital_status, is_child, home, workplace, zeo_age,
zeo_address, requ, monologue, img_url])
print(r'***妹子信息数据保存成功:{}'.format(name))
if __name__ == '__main__':
main()
到此这篇关于单身狗福利?Python爬取某婚恋网征婚数据的文章就介绍到这了,更多相关Python爬取征婚数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!