一、groupby函数
Python中的groupby函数,它主要的作用是进行数据的分组以及分组之后的组内的运算,也可以用来探索各组之间的关系,首先我们导入我们需要用到的模块
首先导入我们所需要用到的数据集
customer = pd.read_csv("Churn_Modelling.csv")
marketing = pd.read_csv("DirectMarketing.csv")
我们先从一个简单的例子着手来看,
customer[['Geography','Gender','EstimatedSalary']].groupby(['Geography','Gender']).mean()
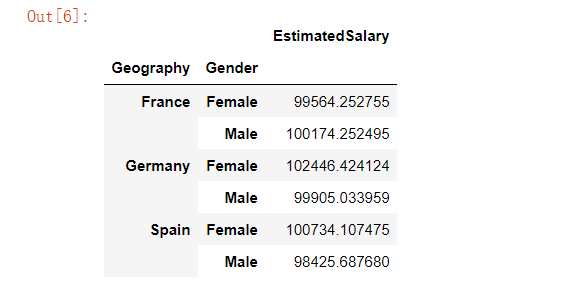
从上面的结果可以得知,在“法国”这一类当中的“女性(Female)”这一类的预估工资的平均值达到了99564欧元,“男性”达到了100174欧元
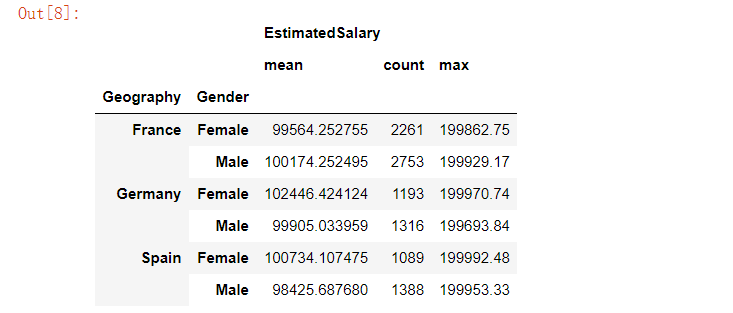
当然除了求平均数之外,我们还有其他的统计方式,比如“count”、“min”、“max”等等,例如下面的代码
customer[['Geography','Gender','EstimatedSalary']].groupby(['Geography','Gender']).agg(['mean','count','max'])
当然我们也可以对不同的列采取不同的统计方式方法,例如
customer[['Geography','EstimatedSalary','Balance']].groupby('Geography').agg({'EstimatedSalary':'sum', 'Balance':'mean'})
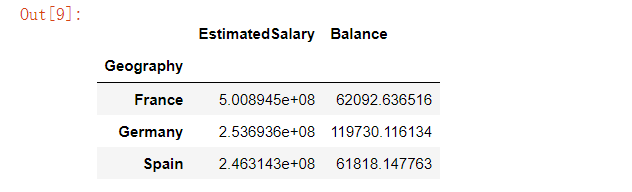
我们对“EstimatedSalary”这一列做了加总的操作,而对“Balance”这一列做了求平均值的操作
二、Crosstab函数
在处理数据时,经常需要对数据分组计算均值或者计数,在Microsoft Excel中,可以通过透视表轻易实现简单的分组运算。而对于更加复杂的分组计算,“Pandas”模块中的“Crosstab”函数也能够帮助我们实现。
例如我们想要计算不同年龄阶段、不同性别的平均工资,同时保留一位小数,代码如下
pd.crosstab(index=marketing.Age, columns=marketing.Gender, values=marketing.Salary, aggfunc='mean').round(1)

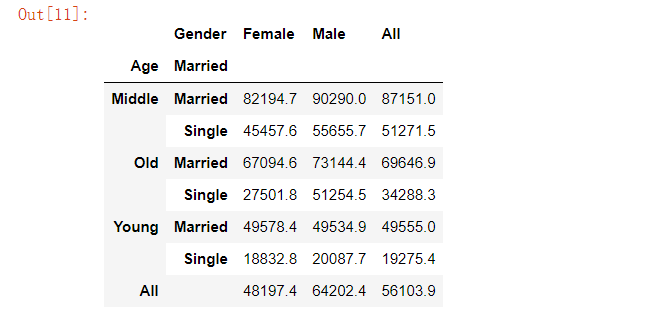
当然我们还可以用该函数来制作一个更加复杂一点的透视表,例如下面的代码
pd.crosstab(index=[marketing.Age, marketing.Married], columns=marketing.Gender,values=marketing.Salary, aggfunc='mean', margins=True).round(1)
三、Pivot_table函数
和上面的“Cross_tab”函数的功能相类似,对于数据透视表而言,由于它的灵活性高,可以随意定制你的分析计算要求,而且操作性强,因此在实际的工作生活当中被广泛使用,
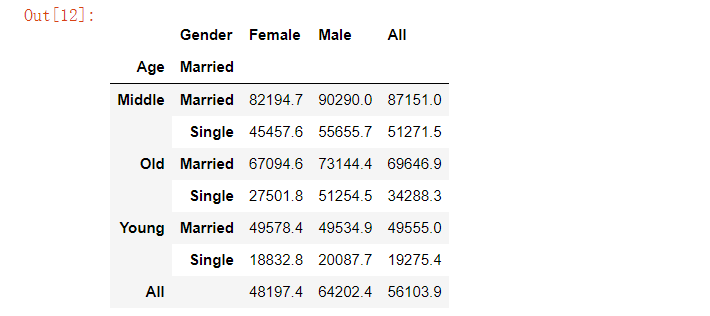
例如下面的代码,参数“margins”对应表格当中的“All”这一列
pd.pivot_table(data=marketing, index=['Age', 'Married'], columns='Gender', values='Salary', aggfunc='mean', margins=True).round(1)
四、Sidetable函数
“Sidetable”可以被理解为是“Pandas”模块中的第三方的插件,它集合了制作透视表以及对数据集做统计分析等功能,让我们来实际操作一下吧
首先我们要下载安装这个“Sidetable”组件,
五、Freq函数
首先介绍的是“Sidetable”插件当中的“Freq”函数,里面包含了离散值每个类型的数量,其中是有百分比形式来呈现以及数字的形式来呈现,还有离散值每个类型的累加总和的呈现,具体大家看下面的代码和例子
import sidetable
marketing.stb.freq(['Age'])

“Age”这一列有三大类分别是“Middle”、“Young”以及“Old”的数据,例如我们看到表格当中的“Middle”这一列的数量有508个,占比有50.8%
marketing.stb.freq(['Age'], value='AmountSpent')

例如上面的代码,显示的则是比方说当“Age”是“Middle”的时候,也就是中年群体,“AmountSpent”的总和,也就是花费的总和是762859元
六、Missing函数
“Sidetable”函数当中的“Missing”方法顾名思义就是返回缺失值的数量以及百分比,例如下面的代码,“History”这一列的缺失值占到了30.3%

七、Counts函数
“Sidetable”函数当中的“counts”方法用来计算各个类型的离散值出现的数量,具体看下面的例子
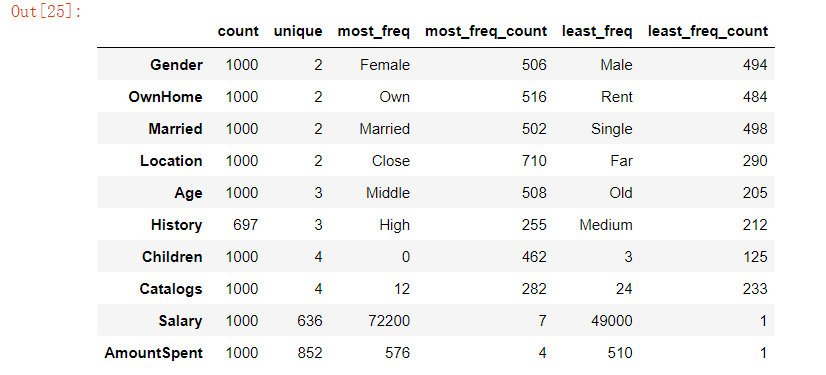
例如“Gender”这一列中,总共有两个,也就是“unique”这一列所代表的值,其中“Female”占到的比重更大,有506个,而“Male”占到的比重更小一些,有494个
到此这篇关于Python Pandas模块实现数据的统计分析的方法的文章就介绍到这了,更多相关Pandas模块实现数据的统计分析内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- 基于Python数据分析之pandas统计分析
- python中pandas对多列进行分组统计的实现
- 详解python pandas 分组统计的方法
